
Ⅰ. 서 론
SAR(synthetic aperture radar)는 항공기나 위성 등에 탑재되어 지표면을 향해 전파를 방사하고, 반사된 신호를 합성하여 영상을 만드는 레이다 시스템이다. SAR 시스템은 지상 표적의 위치, 크기에 대한 고해상도 영상 정보를 제공하며, 악천후, 야간, 구름, 연무 등 다양한 관측 환경에서도 안정적으로 동작한다. 또한, 레이다가 이동하는 동안 다양한 위치에서 신호를 연속적으로 수신하여 넓은 영역을 관측할 수 있다. 최근 들어, 단순히 지형 및 표적에 대한 영상 획득을 넘어 복수의 채널에서 얻은 신호로부터 형성한 복수의 SAR 영상을 이용하여 영상 내 이동 표적을 탐지하는 GMTI(ground moving target indication)에 관한 연구가 활발히 진행되고 있으며 대표적인 기법으로는 ATI(along track interferometry), DPCA(displaced phase center antenna) 등이 있다[1]. 두 기법 모두 일정한 간격을 두고 분리된 안테나에서 취득한 신호로 형성된 영상을 이용한다. 각 채널이 동일한 위치에 있을 때 동일한 영역을 관찰하여 얻은 SAR 영상을 이용하며, 정지 표적의 경우 표적이 각 채널 영상에서 같은 값을 가지지만 이동 표적의 경우 채널별 영상에서 다른 값을 가지는 특징을 이용한다.
DPCA는 복수의 영상 간의 차이를 이용하여 이동 표적을 탐지하며 계산량이 낮은 장점이 있어 실시간 구현에 장점이 있다. ATI는 복수의 SAR 영상 간의 켤레 곱을 구하여 인터페로그램을 형성하고 해당 인터페로그램의 위상 성분을 이용하여 이동 표적을 탐지하며 위상 성분을 이용하여 이동 표적의 속도를 추정할 수 있다는 장점이 존재한다[2]. 두 기법을 적용한 결과는 정지 표적의 경우 0에 가까운 값을 가지며 이동 표적은 0이 아닌 값을 가지므로 기법을 적용한 결과에 CFAR(constant false alarm rate) 탐지기를 적용하여 이동 표적을 탐지한다. CFAR는 임곗값을 조절하여 일정한 오경보율을 유지하면서 표적을 탐지하는 기법으로 주변 잡음 또는 클러터 수준을 기준으로 임곗값을 설정하기 때문에 효과적으로 표적을 탐지할 수 있다는 장점이 있다[3].
CFAR 기반의 정확한 표적 탐지를 위해서는 가드 셀, 트레이닝 셀 등의 파라미터를 표적의 크기 등에 따라 적절히 설정하여 CFAR 검출기의 임곗값을 최적화하는 것이 필수적이다[4]. 하지만 다양한 환경에서 취득되는 SAR 영상에서는 적절한 파라미터를 찾기 어려워 성능이 크게 변동하는 문제가 발생할 수 있다. 이러한 문제를 극복하고자, 본 연구에서는 입력 데이터에서 스스로 이동 표적 탐지에 필요한 특징을 학습하는 딥러닝 모델을 이용하여 이동 표적을 탐지하는 기법을 제안한다. YOLO(you only look once) 모델을 기반으로 SAR 영상 내 이동 표적을 탐지하는 모델을 설계하고, 2채널 SAR 영상의 크기와 위상을 이용하여 모델을 학습시킨다. 제안된 이동 표적 탐지 모델의 성능을 평가하기 위하여 이동 표적, 정지 표적, 클러터 성분이 존재하는 SAR 영상을 형성하고 영상 내 표적에 대한 탐지 성능을 평가하였다.
Ⅱ. SAR 시스템 및 신호 모델
SAR 시스템에서 송신되는 신호는 주로 선형 주파수 변조 방식을 사용한다. 선형 주파수 변조 신호는 시간에 따라 주파수가 선형적으로 변화하며, 이러한 변조 방식을 적용하여 송신된 신호와 표적에 반사되어 돌아오는 수신 신호 간의 시간 지연을 분석해 거리 정보를 추정할 수 있다. 송신 신호는 식 (1)과 같이 표현된다.
여기서, A, f0, K는 각각 신호의 진폭, 작동 주파수, 주파수 변조율을 의미한다. 송신 신호는 표적에 반사되어 수신기로 돌아오며, 반사된 신호는 표적까지의 거리 R, 표적의 이동 속도 v, 전파 속도 c에 따라 시간 지연 과 도플러 편이 를 포함하게 된다. 반사되어 수신되는 신호는 식 (2)와 같이 표현된다.
여기서 Ar는 수신 신호의 진폭을 의미하며, 수신 신호의 위상과 주파수 변화를 분석하여 표적까지의 거리와 상대 속도를 추정할 수 있다.
플랫폼이 이동하면서 다양한 위치에서 수신된 SAR 신호는 이동 궤적에 따라 시간과 공간 정보를 포함하게 된다. 각기 다른 시점에서 수신된 신호는 정합 필터링과 거리 보정 과정을 통해 시간과 공간 축에 맞게 정렬된다. 즉, 플랫폼의 이동 경로에 따라 수신된 신호들이 시간 축과 거리 축에서 정확히 배치되어, 일관된 거리와 방위 정보를 제공하도록 조정된다. 이를 통해 긴 가상의 안테나가 형성되며, 고해상도 영상을 형성할 수 있다.
영상 형성을 위해 사용되는 대표적인 기법에는 RDA(range-Doppler algorithm)과 RMA(range migration algorithm)이 있다[5]. RDA는 신호를 주파수 영역으로 변환해 표적의 거리와 방위각 정보를 추정한다. 시간 지연을 기반으로 거리 정보를 계산하고, 플랫폼의 이동에 따른 도플러 주파수 변화를 분석해 방위각을 추정한다.
RMA는 비선형 경로로 이동하는 플랫폼에 적합하며, 신호 왜곡을 바로잡는 데 특화되어 있다. 시간 지연과 주파수 도플러 변화를 동시에 고려하여, 비선형 궤적에서 발생하는 거리 이동에 따른 신호 왜곡을 복원한다. RDA와 달리, 플랫폼이 곡선 경로를 따라 이동하거나 고속으로 기동할 때도 신호 왜곡을 효과적으로 보정하여 더 정확한 거리 정보를 제공한다. 또한, RMA는 더 넓은 관측 범위에서 높은 해상도를 제공하므로 복잡한 환경에서도 우수한 성능을 발휘할 수 있다. 따라서 본 논문에서는 RMA 방식을 채택하였다.
Ⅲ. 기존 SAR GMTI 기법
SAR 시스템을 이용한 이동 표적 탐지에서 널리 이용되는 시스템은 2채널 수신 구조를 채택한 구조이다. 이 시스템은 항공기나 위성에 탑재된 SAR 시스템이 복수의 수신 안테나를 사용하여 같은 영역을 서로 다른 시간에 관측함으로써 표적의 움직임에 따른 위상 변화를 포착할 수 있다. 그림 1은 2채널 SAR 플랫폼의 예시로 두 수신 안테나가 일정 거리만큼 이격된 것을 보여주는 그림이다. 채널 1의 신호 s1 과 채널 2의 신호 s2는 식 (3)과 같이 표현할 수 있으며,
d는 채널 간 간격, λ는 파장을 의미한다. 위 수식에서 볼 수 있듯이 두 영상 간에는 표적의 속도에 비례하는 위상 차이가 발생하게 되며, 따라서 이동 표적의 탐지가 가능하다. 이러한 두 영상 간의 위상 차이를 탐지할 수 있도록 하는 대표적인 다중 채널 기반의 GMTI 기법으로는 DPCA와 ATI가 있다[6].
DPCA는 2채널 SAR 시스템에서 두 개의 안테나를 이용해 동일한 영역을 연속적으로 관측하고, 각 안테나에서 수신된 신호의 차이를 이용하는 방식이다. 이는 식 (4)와 같이 표현된다.
S1과 S2는 각 채널에서 얻어진 SAR 영상이다. 이동 표적이 존재하지 않을 경우, 채널 간 SAR 영상에 차이가 없다. 반면, 이동 표적이 존재하면 채널 간 간격에 따른 관측 시점의 차이로 인해 영상 간의 차이가 발생한다. 따라서 DPCA를 적용하면 0이 아닌 값을 나타내어 이동 표적을 탐지할 수 있다[2]. 기존 DPCA 비균질 클러터 환경에서 성능 하락이 발생할 수 있으므로 DPCA와 두 영상 간의 위상 차이를 사용하는 WDPCA(weighted DPCA) 기법을 사용할 수 있으며 이는 식 (5)처럼 표현할 수 있다[7].
ATI는 SAR 영상의 켤레곱을 이용하여 SAR 영상 간의 위상 차이를 분석하고, 이를 통해 이동 표적을 탐지하는 기법으로 식 (6)과 같이 표현된다.
이동 표적의 경우 영상 간 위상 차이가 발생하므로 ATI를 적용한 결과에서 위상이 0이 아닌 값을 찾는 방식으로 이동 표적을 탐지한다. 이때 두 영상간의 위상 차이는 이동 표적의 속도에 비례하며 이는 이는 식 (7)과 같이 계산된다[8].
여기서 vp는 SAR 플랫폼의 이동 속도를 나타내며, λ는 파장, d는 수신 안테나 사이 간격을 의미한다. 이때 영상 간의 위상 차이만을 이용한 탐지는 실제 SAR 영상에 적용 시 많은 오경보를 유발하므로 켤레 곱의 크기와 위상을 동시에 이용하는 ATI IMP(interferometry magnitude and phase) 기법을 이용할 수 있으며, 이는 식 (8)과 같이 표현된다[2],[9].
Ⅳ. 제안된 YOLO 기반 SAR-GMTI 기법
본 연구에서 제안하는 이동 표적 탐지 기법은 YOLO 모델을 기반으로 한다. YOLO 모델은 실시간 객체 탐지를 위한 대표적인 딥러닝 기법으로, 단일 신경망을 사용하여 이미지에서 객체의 위치와 클래스 정보를 동시에 추정하는 구조를 가진다. YOLO 모델은 입력 이미지를 일정 크기의 그리드로 분할하며, 각 그리드 셀은 고정된 개수의 경계 상자와 그에 해당하는 객체의 클래스 확률을 예측한다. 각 경계 상자는 영상에서 객체의 위치인 중심 좌표와 크기(너비, 높이), 그리고 존재 여부를 나타내는 신뢰도 점수를 포함한다[10]. 모델의 손실 함수는 경계 상자의 정확한 위치 예측과 클래스 분류 간의 균형을 유지하도록 설계되어 있으며, 이를 통해 객체 탐지와 분류의 종합적인 성능을 최적화한다.
YOLO 모델의 구조는 크게 백본, 넥, 헤드로 세 부분으로 나뉜다. 백본은 YOLO 모델에서 입력 이미지로부터 특징을 추출하는 역할을 담당하는 신경망이다. 주로 합성곱 신경망 구조로 구성되어 있으며, 이미지 내에서 객체를 인식하는 데 필요한 저수준부터 고수준까지의 다양한 특징을 추출한다. 백본은 여러 계층으로 구성되어 입력 이미지의 공간적 정보를 축소하면서 중요한 특징을 강조하며, 추출된 특징 맵은 이후 단계에서 객체의 위치와 크기를 예측하는 데 사용된다. 넥은 백본에서 추출된 특징을 강화하고 다중 스케일의 정보를 통합하여 객체 탐지 성능을 개선한다. 이를 통해 표적의 위치와 크기에 관계없이 YOLO 모델이 정확한 탐지를 수행할 수 있도록 한다. 헤드는 넥에서 전달받은 특징 맵을 사용하여 최종적인 객체 탐지 결과를 산출하는 부분이다. 헤드에서 각 그리드 셀마다 경계 상자와 해당 상자 내 객체의 클래스 확률을 예측한다.
YOLO 기반 이동 표적 탐지 기법의 입력은 복수의 채널에서 얻어진 SAR 영상의 위상 성분을 이용한다. SAR 영상은 복소수 형태로 표현되므로, 본 연구에서 제안한 기법은 SAR 복소수 데이터를 그대로 사용하는 대신, 위상 정보를 입력 데이터로 활용한다. 영상 내 이동 표적에 해당하는 영역은 속도에 비례하는 위상 차이가 발생하므로, SAR 영상의 위상 성분을 입력으로 사용함으로써 이동 표적의 특징을 더 효과적으로 파악할 수 있다. n번째 채널에서 얻은 신호로 형성한 SAR 영상의 동위상과 직교위상 성분을 이용하여 얻은 영상의 위상은 식 (9)처럼 표현된다.
총 N개의 채널이 존재한다고 가정하면, SAR 영상의 위상 성분 Pn으로 구성된 입력 데이터와 위상 성분만으로 구성된 데이터는 식 (10)과 같이 표현된다.
이때 일반적인 영상 대비 더 큰 수의 화소를 갖는 SAR 영상의 특성상 영상 전체를 입력으로 사용하는 것이 아닌 각 SAR 영상을 복수의 부영상으로 분할하여 학습에 사용하였다. 분할된 각각의 부영상에 대해 이동 표적에 해당하는 영역을 라벨링 하였으며, 라벨링 된 경계 상자는 표적에 해당하는 화소 중 가장 크기가 큰 값을 갖는 화소 대비 절반의 이상의 값을 갖는 화소들을 포함하도록 설정하였다.
라벨링 된 2채널 SAR 영상의 위상 정보를 입력받은 YOLO 기반 이동 표적 탐지 모델은 먼저 백본에서 합성곱 신경망 구조를 활용하여 입력된 위상 맵에서 단순 윤곽선 정보나 특정 화소 사이 위상 차이 등 하위 레벨과 SAR 영상 내에서 배경과 이동 표적의 구분되는 전반적인 구조적인 차이에 해당하는 상위 레벨 특징을 추출한다. 추출된 다양한 스케일의 특징 맵은 넥의 spatial pyramid pooling 모듈에서 결합되며 동시에 path aggregation network에서 상위 및 하위 레벨 특징 맵 간의 업샘플링 혹은 다운 샘플링 후 효과적인 상호 결합을 통해 영상 간 이동 표적의 위상 차이에 해당하는 특징을 추출한다. 이러한 과정을 통해 얻어진 고차원 특징 맵은 헤드로 전달되어 바운딩 박스와 클래스 확률로 변환되며 최종적으로 이동 표적이 존재하는 영역과 신뢰도 점수를 출력한다. 제안된 기법의 프레임워크는 그림 2와 같다.
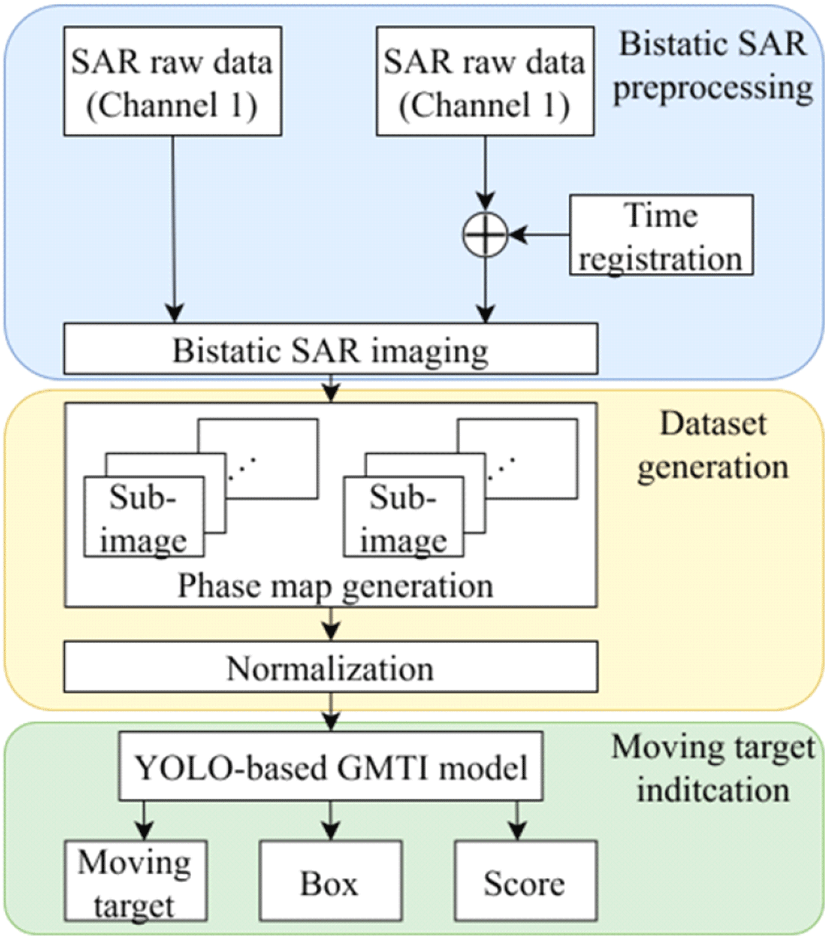
Ⅴ. 모의실험 및 결과
제안된 기법을 검증하기 위하여 모의실험을 수행하였다. 모의실험에서 사용된 시나리오는 다음과 같다. SAR 시스템은 1.8 GHz의 대역폭에서 동작하는 X 밴드 2채널 SAR 시스템이며, 항공기 플랫폼을 가정하였다. 각 플랫폼의 운용 고도는 5 km이며, 송수신 플랫폼 모두 300 m/s의 속도로 움직이는 along-track 구조의 바이스태틱 시스템을 가정하였다. 이때 송수신 플랫폼 사이의 거리는 500 m를 가정하였다. 수신기 사이 간격은 0.4 m로 지정하였다. 또한 이동 표적의 속도는 −10 m/s에서 10 m/s까지 0.2 m/s 간격으로 설정하였다. 모의실험에서 사용된 시나리오의 예시는 그림 3과 같다. 앞서 언급한 대로 본 연구에서 YOLO 모델의 학습은 하나의 SAR 영상을 일정한 크기로 분할하며, 이때 하나의 부영상이 해당하는 영역에서는 최소 하나의 이동 표적이 포함되며 그 외의 정지 표적은 랜덤하게 분포되도록 하였다. 또한 영상 내 표적의
위치가 이동 표적 탐지의 영향을 미치지 않게 하게 하도록 하나의 부영상의 영역을 고려하여 표적의 위치를 설정하여 영상 내 다양한 위치에서 표적들이 존재하도록 하였다.
2채널 바이스태틱 SAR 신호를 생성한 후 SAR 영상 형성을 위해 RMA를 활용하였다[11]. 이를 통해 형성한 SAR 영상의 크기는 1,024×512이며 해당 영상을 100×100 크기의 부영상 50개로 분할한다. 이후 형성한 영상을 더욱 현실적으로 구현하기 위하여 클러터 성분을 추가하였다. 클러터 성분의 크기는 rayleigh 분포를 따르며 위상의 경우 균등 분포를 따르도록 설정하였다[12]. 또한 SAR 영상 간의 복소 상관 계수의 크기가 0.9~0.95 사이가 되도록 클러터 성분의 크기와 위상을 조절하였다[2],[13]. 다양한 SCNR(signal-to-clutter and noise ratio)에서의 제안된 기법의 성능을 평가하기 위하여 SCNR을 −5 dB에서 5 dB까지 증가시키며 형성된 SAR 영상에 클러터 화소를 생성하였으며, 이때 SCNR은 식 (11)과 같이 정의하였다.
식 (11)에서 σt는 이동 표적 화소의 크기, σc,i는 이동 표적 외에 i번째 클러터 화소의 크기이며, K는 영상 내 클러터 화소의 개수이다.
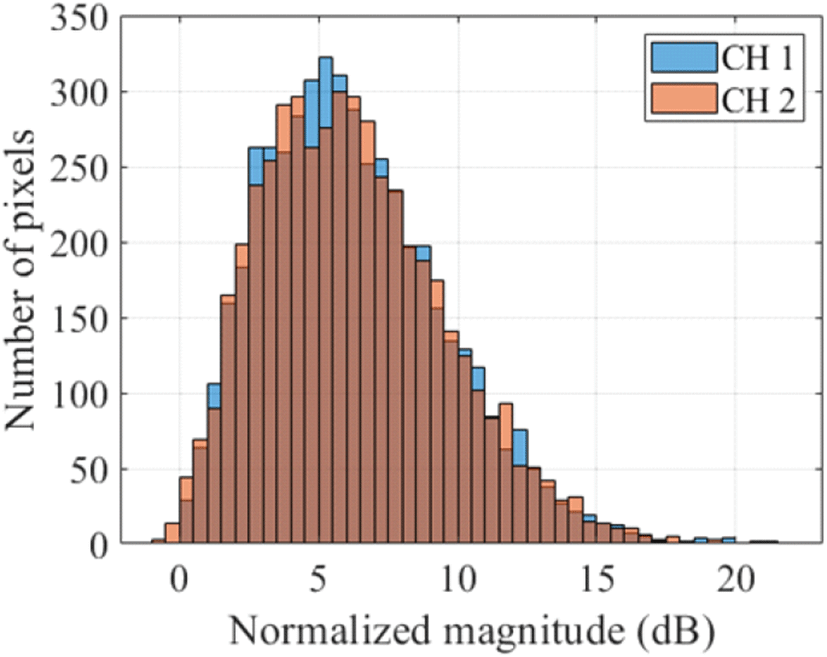
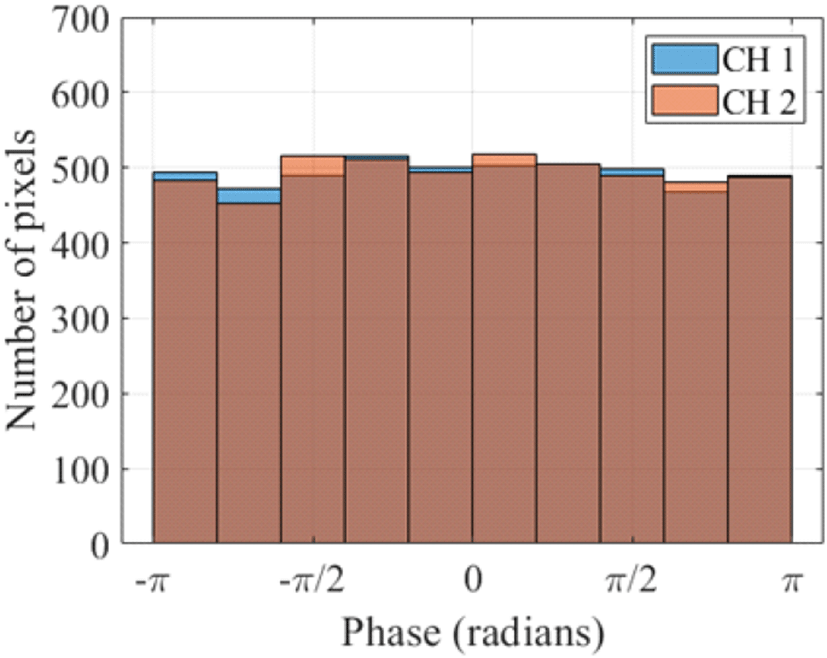
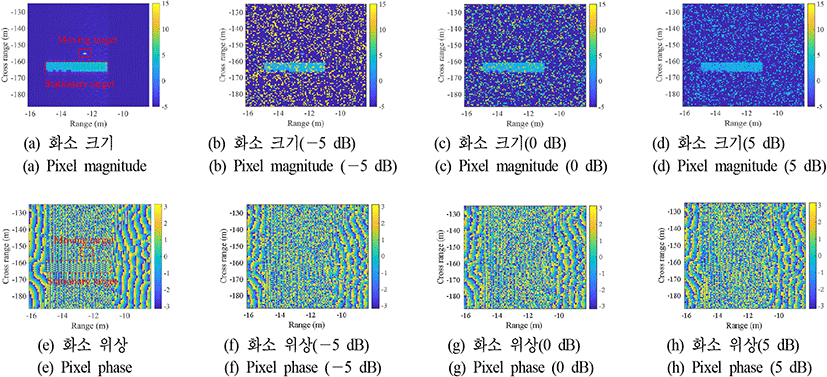
본 연구에서는 100×100크기로 분할된 영상에 대해서 하나의 영상당 5,000개의 클러터 화소를 랜덤하게 영상에 분포시켰다. 이를 통해 클러터가 포함된 100×100×2 크기의 SAR 영상의 위상 데이터셋을 생성하였다. 그림 4 및 그림 5는 SCNR이 5 dB가 되도록 형성한 SAR 영상의 크기와 위상의 분포를 히스토그램으로 나타낸 것으로, 영상 간에 클터터 화소의 크기와 위상의 차이가 있는 것을 확인할 수 있다. 그림 6은 모의 실험을 통해 형성한 SAR 영상의 SCNR이−5, 0, 5 dB가 되도록 클러터 화소를 추가한 영상들의 크기와 위상을 보여주며영상의 중앙에 그림 3에서 차량에 해당하는 이동하는 표적과 그 아래 건물에 해당하는 정지 표적을 확인할 수 있다.
YOLO 기반 이동 표적 탐지 모델의 입력으로 사용될 위상 성분의 경우 최대 최소 정규화 기법을 사용하였으 며, 이때 최댓값은 π, 최솟값은 −π의 고정된 값을 사용하였다. 모의실험을 통해 취득한 총 48,000개의 영상의60 %를 학습, 20 %를 검증용으로 분할하고, 나머지 20 %를 이용하여 제안된 기법의 성능을 평가하였다. 이때 학습 데이터는 랜덤하게 크기조정, 회전, 상하좌우 반전, 평행 이동의 기법을 적용하여 학습 데이터에 대한 과적합을 방지하였다. YOLO의 백본으로는 Resnet50을 사용하였으며, 학습은 RTX 4080 GPU를 이용하여 이루어졌다. 배치 크기는 64, 최대 에포크는 10으로 설정하고, 학습에는 adaptive moment estimation 최적화 함수를 이용하였다. 기울기 감소 계수는 0.9, 제곱 기울기 감소 계수는 0.999로 설정되었다. 초기 학습률은 0.001로 설정했으며 과적합을 방지하기 위해 손실 함수에 대한 가중치에 대해 L2 정규항을 추가하였으며 정규화 계수값은 0.0005로 설정하였다. YOLO 모델의 앵커 상자의 개수 설정을 위해서는 앵커 상자의 개수를 1개에서 15개까지 변화해가며 앵커 상자와 학습 데이터의 실제 경계 상자와의 intersection of union의 변화를 분석한 결과, 앵커 박스의 개수가 8개를 초과할 경우 IoU 값이 수렴하는 경향을 보였다. 이에 따라 YOLO 모델의 앵커 박스의 개수를 8개로 설정하였다.
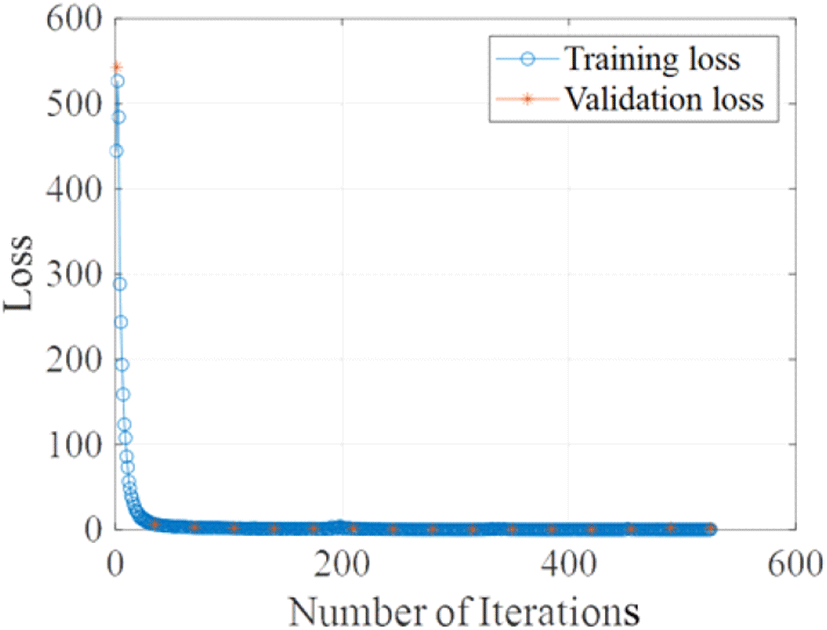
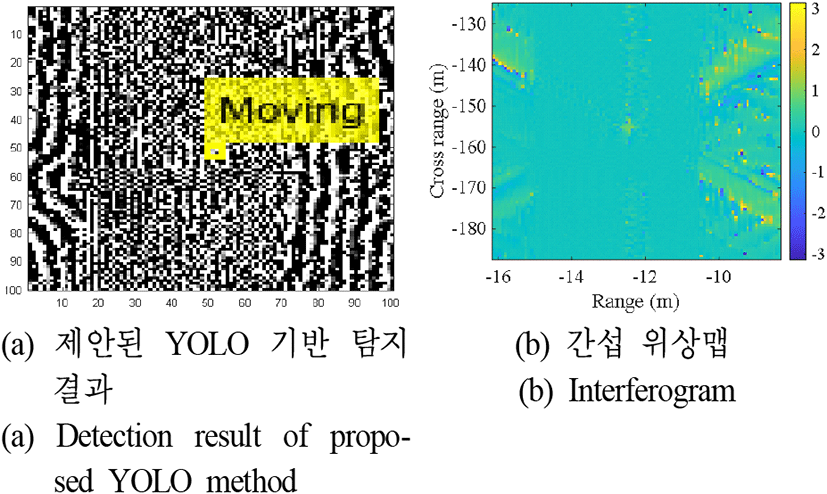
해당 모델은 최대 10번의 에포크 동안 학습되며 각 에포크 시작 시 입력 데이터를 섞어 학습의 강인성을 높였다. 검증은 35회의 반복마다 수행되며, 검증 손실이 10회 반복 동안 감소하지 않으면 학습을 중단하였다. 그림 7은 YOLO 기반 이동 표적 탐지 모델의 반복 학습에 따른 훈련 손실과 검증 손실의 변화를 보여준다. 학습이 반복됨에 따라 학습 손실은 점차 감소하며 565번째 반복에서 최솟값인 0.1725를 기록하였다. 검증 손실은 425번째 반복에서 최솟값인 0.2452를 기록한 뒤, 소폭 증가하는 경향을 보였다. 이는 모델이 425번의 반복 학습 이후로는 학습 데이터에 과적합 되었음을 나타내므로 425번째 반복에서 학습을 중단하였다. 그림 8은 학습을 마친 이동 표적 탐지 모델을 이용하여 SAR 영상 내 이동 표적을 탐지한 결과를 보여준다. 탐지 결과와 두 영상 간의 간섭 위상을 보여주는 간섭 위상 맵과의 비교를 통해 제안된 YOLO 기반 이동 표적 탐지 모델이 영상 내에서 이동 표적이 존재하여 위상 차이가 발생한 화소를 탐지하였음을 확인할 수 있고 이를 통해 SAR 영상 내 표적의 이동에 따른 위상의 차이를 인식하여 이를 탐지한 것을 확인하였다.
제안된 YOLO 기반의 이동 표적 탐지 기법의 성능을 ATI-IMP와 WDPCA 기법 적용 결과에 greatest-of cell-averaging CFAR(GOCA-CFAR) 탐지기를 이용하여이동 표적을 탐지한 결과와 비교하였다. GOCA-CFAR 탐지기는 비균질 환경에서 탐지성능이 저하되는 CA-CFAR의 단점을 극복하고자 관심 영역 주변의 참조 윈도우를 선행과 후행으로 나누어 각 부분의 평균값 중 더 큰 값을 기반으로 임계값을 설정한다. 이를 통해 CA-CFAR 대비 계산량의 큰 증가 없이도 강인한 표적 탐지 성능을 제공한다[14],[15]. CFAR 탐지기의 가드셀의 크기는 (5, 5), 트레이닝 셀의 크기는 (10, 10)으로 설정하였으며, 제안된 YOLO 기반 기법과 오경보율이 비슷한 조건에서의 탐지 성능 비교를 위하여 ATI-IMP 기법의 경우 5×10−6를, WDPCA 기법의 경우 10−5을 사용하였다. 그림 9~그림 11은 SCNR이 −5, 0, 5 dB일때의 영상에 대해 ATI-IMP와 WDPCA를 기반으로 이동 표적을 탐지한 결과 예시를 보여준다.
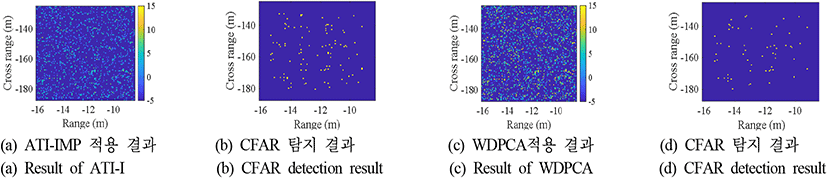
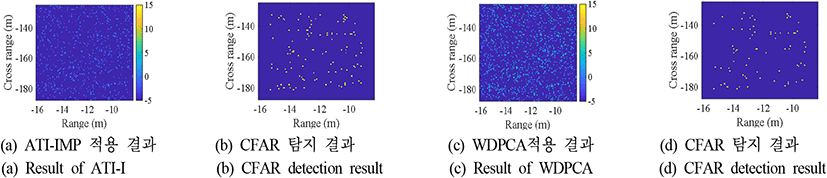
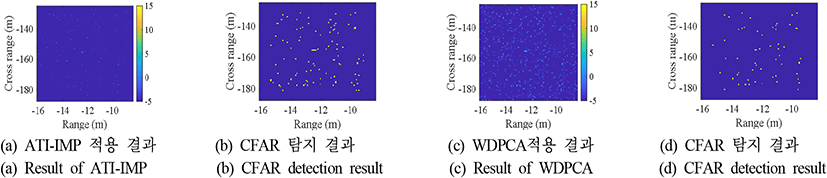
제안된 기법과 기존 GMTI 기법과의 성능 비교를 위한 지표로는 탐지율과 오경보율을 사용하였다. 탐지율은 영상 내 이동 표적이 존재하는 영역을 성공적으로 탐지하는 비율을 의미하며, 오경보율은 탐지된 화소 중 이동 표적이 존재하지 않은 영역에 해당하는 화소 개수의 비율로 정의하였다. 이때 YOLO 기반 이동 표적 탐지 모델은 신뢰도 점수가 0.3 이상인 경계 상자만 출력하도록 하였으며, 예측된 경계 상자의 크기와 실제 경계 상자의 넓이가 50 % 이상 겹칠 경우 표적 탐지가 성공하였다고 판별하였다. 그 외 경우에는 경계 상자의 넓이만큼의 화소에 대해 오경보가 발생하였다고 판별한다. ATI-IMP 기법과 WDPCA의 경우 탐지된 화소가 실제 경계 상자 내에 포함되었는지를 기준으로 삼았다.
그림 12는 SCNR을 −5 dB에서 5 dB까지 변화해가며 GMTI를 수행한 결과를 보여준다. 그림 12 (a)에서 볼 수 있듯이 제안된 YOLO 기반의 이동 표적 탐지 모델은 −5 dB에서 5 dB 구간에서 98 % 이상의 확률로 이동 표적을 탐지하는 데 성공하였다. 기존 GMTI 기법들의 경우 SCNR이 0 dB 이하에서는 50 % 이하의 탐지 확률을 보여주었으며 SCNR이 증가할수록 탐지 확률도 같이 증가하는 양상을 보였다. ATI-IMP와 WDPCA 기법 모두 SCNR 5 dB에서 가장 높은 탐지 확률을 보였으며 ATI-IMP 기법이 YOLO 기반 기법 다음으로 높은 87 %의 이동 표적 탐지율을 보였다. WDPCA 기법은 83 %의 이동 표적 탐지율을 보였다. 또한 그림에서 확인할 수 있듯이 모든 SCNR 구간에서 제안된 YOLO 기반 이동 표적 탐지 기법이 기존 ATI-IMP와 WDPCA 기법보다 향상된 이동 표적 탐지율을 보여주었다. 그림 12(b)는 각 기법의 오경보율을 보여준다. 그림에서 볼 수 있듯이 제안된 YOLO 기반 기법은 평균 0.24 %의 오경보 화소가 탐지되었으며, SCNR 변화에도 오경보율에는 큰 변화가 일어나지 않았다. 또한 ATI-IMP와 WDPCA 기법도 CFAR 탐지기의 특성상 SCNR의 변화에도 일정한 값을 유지하는 것을 확인할 수 있다.
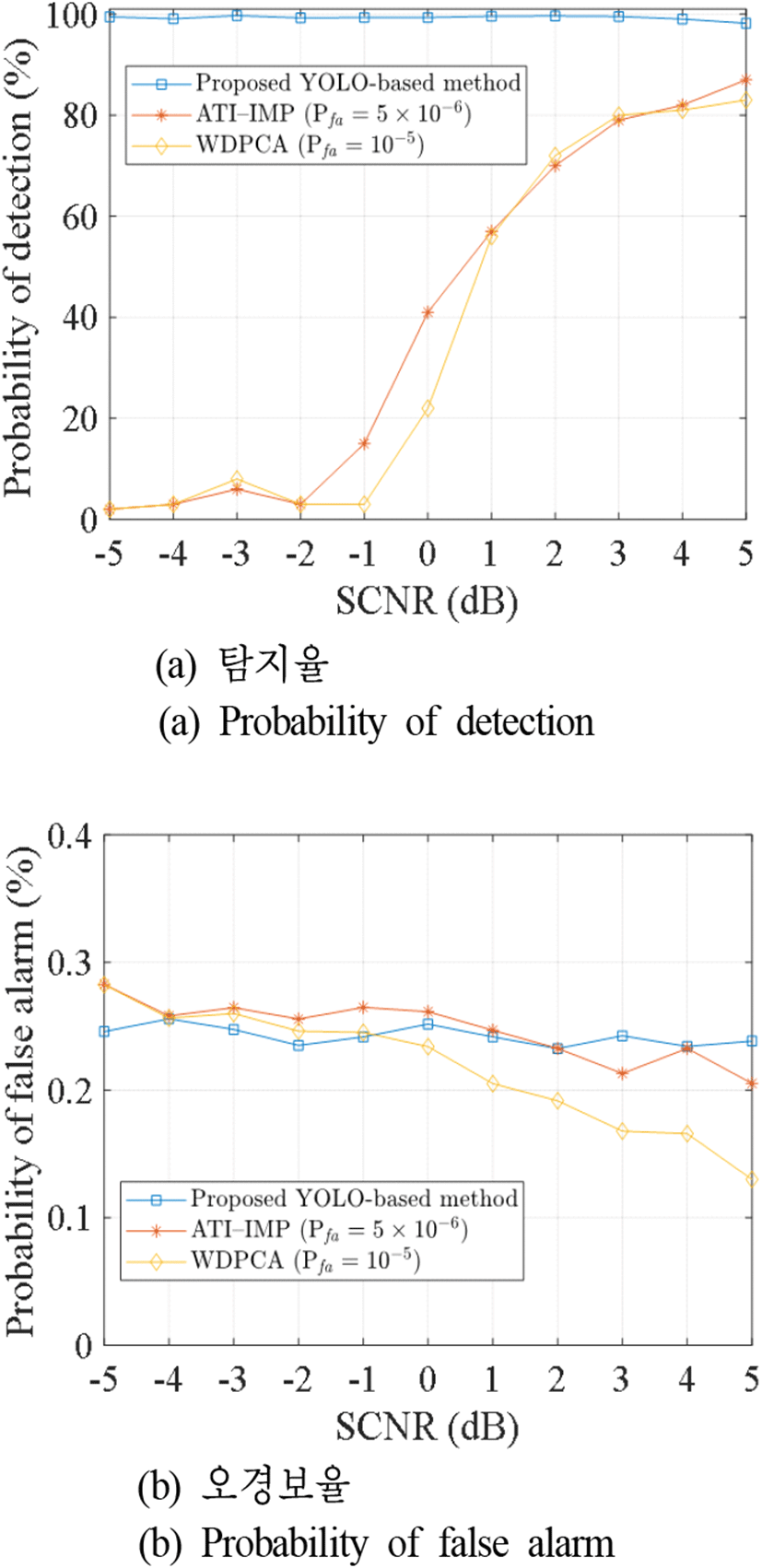
또한 앞서 언급한 대로 오경보율이 비슷한 조건에서 표적 탐지 성능을 비교하기 위하여 CFAR 탐지기의 설정 오경보율을 조절하였기 때문에 기존 GMTI 기법의 오경보율이 제안된 YOLO 기반의 이동 표적 기법의 오경보율과 비슷한 것을 확인할 수 있다. ATI-IMP 기법이 평균 0.24 %의 오경보율을 보였으며, WDPCA 기법은 평균 0.22 %의 오경보율을 보여주었다. 그림 11(a) 및 그림 11(b)를 비교할 경우 CFAR 탐지기를 이용하는 ATI-IMP 기법과 WDPCA 기법의 경우 오경보율과 탐지율이 비례하는 일반적인 경향에 부합함을 확인할 수 있다. 또한 기존 기법의 경우 SCNR −5 dB에서 최소 탐지율인 2 %를 보였으며, 0 dB 이하에서는 50 % 이하의 낮은 탐지율을 보이나 SCNR이 증가함에 따라 탐지율이 점진적으로 향상되어 SCNR 5 dB 이상에서는 80 % 이상의 탐지율을 보였다. 이는 낮은 SCNR 조건에서는 GMTI 기법을 적용하더라도 잔여 클러터 성분의 크기가 표적 성분의 크기와 비슷하여 CFAR 탐지기가 표적과 클러터를 명확하게 구분하기 어렵기 때문이다. 반면, 높은 SCNR 조건에서는 클러터 대비 이동 표적 성분의 크기가 뚜렷하게 구분되어 탐지율이 향상된다. 반면, 제안된 YOLO 기반의 이동 표적 탐지 기법은 모든 SCNR에서 기존 기법들보다 우수한 탐지 성능을 보여주었으며, 특히 낮은 SCNR 조건에서 기존
기법들보다 우수한 탐지율을 보였다. 이는 YOLO 모델을 구성하는 합성곱 신경망이 다양한 SCNR과 이동 표적의 속도 등의 조건 속에서 생성된 학습 데이터를 기반으로 이동 표적의 비선형적이고 복잡한 특성을 추출하고 효과적으로 학습하여, 기존 GMTI 기법과 CFAR 탐지기를 이용하여서는 탐지가 어려운 환경에서도 표적을 탐지할 수 있기 때문으로 분석된다.
SCNR이 높아질수록 기존 GMTI 기법의 적용 결과에서 표적 성분이 뚜렷하게 나타나면서 기존 기법들의 성능도 향상되며, 이에 따라 제안된 기법과 기존 기법 간의 성능 격차는 감소하지만 제안된 기법은 향상된 탐지성능을 유지하며 ATI-IMP 기법과 WDPCA 기법 대비 SCNR 1 dB에서 40 %p 이상의 격차와 5 dB에서 12 %p와 17 %p의 성능 격차를 보였다. 이를 통해 제안된 YOLO 기반의 이동 표적 탐지 기법이 기존 GMTI 기법에 비해 동일한 오경보 조건에서 더욱 향상된 탐지성능을 제공함을 확인할 수 있다.
Ⅵ. 결 론
본 연구에서는 YOLO 기반의 신경망을 활용하여 SAR 영상 내 이동 표적 탐지 기법을 제안하였다. YOLO 기반의 이동 표적 탐지 모델을 설계하고 바이스태틱 SAR 영상의 위상 성분을 이용하는 모델과 크기와 위상을 이용하는 모델의 성능을 비교하였다. 또한 기존 GMTI 기법인 DPCA와 ATI를 적용하여 영상 내 이동 표적을 탐지하는 성능을 비교하였다. 제안된 YOLO 기반 이동 표적 탐지 모델은 기존의 DPCA와 ATI 기법과 비교하였을 때 SCNR 1 dB에서 40 %p 이상의 향상된 탐지율과 SCNR 5 dB에서 12 %p와 17 %p의 향상된 탐지율을 보였다. 이를 바탕으로, 실제 바이스태틱 SAR 시스템 테스트베드를 통해 이동 표적이 포함된 SAR 영상을 취득하여 실제 데이터를 기반으로 제안된 기법의 성능을 검증할 계획이다. 이를 통해 높은 탐지율과 낮은 오경보율을 동시에 달성할 수 있는 이동 표적 탐지 기법 개발에 기여하고자 한다.



