
Ⅰ. 서 론
최근 원자력 발전소 실내환경에서도 무선통신을 도입하기 위한 연구가 활발히 진행되고 있다[1]~[3]. 원자력 발전소와 같은 높은 안전성을 요구하는 시설에서 전자기간섭(EMI) 및 전자기호환성(EMC)을 고려하기 위해 다양한 경우에 대한 원전 내에서의 전계강도 분석이 필요하다[4]. 전계강도의 분석에는 RT(ray tracing) 기법이 주로 사용되는데, 다양한 환경 조건에 대해 실내환경에서 전계강도를 얻기 위해 상당한 시간과 비용이 요구된다.
이러한 문제를 해결하기 위해서 최근 인공지능 기법 중 영상의 특성을 데이터로부터 찾아내고 학습하기 위한 기법인 CNN(convolutional neural networks) 기법이 제안되었다[5]. 본 연구에서는 원전 내의 주 제어실 환경에서 전계강도를 효율적으로 예측하기 위하여 RT 시뮬레이터로부터 얻은 데이터를 학습시켜 CNN 모델을 구축한 후 이 모델로부터 새로운 환경에 대해 예측한 전계강도 분포 결과를 RT 기법의 결과와 오차를 비교하여 그 유효성을 검증한다.
본 논문의 Ⅱ장에서는 CNN을 활용한 전계강도 예측기법을 제안하고, Ⅲ장에서는 모의실험을 통하여 원전 주 제어실 환경에서의 전계강도 예측의 유효성을 제시하고, Ⅳ장에서 결론을 맺는다.
Ⅱ. CNN을 활용한 전계강도 예측 기법
본 연구에서는 실내 전파를 학습하고 예측하기 위해 CNN을 사용한다. CNN은 입력 데이터에 대해 필터를 적용하여 지역적 패턴이나 특징을 감지하고, 특징 맵을 생성하는 과정을 반복하여 원하는 출력을 생성할 수 있는 기계학습 모델이다. CNN은 이미지 처리, 컴퓨터 비전, 자연어 처리 등 다양한 분야에서 효과적으로 활용되고 있다[6].
ANN(artificial neural network)은 모든 신경 다발이 연결되어 있어서 파라미터의 최적값을 찾기 어렵고, 과적합 문제로 인해 대규모 데이터나 복잡한 패턴 인식에는 한계가 있다. RNN(recurrent neural network)은 반복적이고 순차적인 데이터 학습에 특화된 구조로, 과거의 학습을 현재 학습에 반영하는 순차적 연산을 수행하나, 대규모 데이터 학습에서는 연산 속도가 느린 단점이 있다. DNN (deep neural network)은 모델의 은닉층을 많이 늘려 학습 결과를 향상시키는 기법이지만, 이미지의 공간적인 특징을 감지하는 데 한계가 있고, 레이어 간 완전한 연결 형태로 많은 파라미터가 필요하다[7]. 이와 달리, CNN은 Convolution 계층과 Pooling 계층을 통해 입력 데이터의 특징을 추출하고 최적화하며, 이를 바탕으로 패턴을 인식한다. 이러한 구조로 CNN은 속도가 빠르고, 데이터량이 적당한 수준으로 효율적인 학습이 가능하다. CNN을 전파 모델링에 적용하는 경우에는 송신안테나 위치, 직접적인 전파 경로(line of sight), 굴절 지점, 장애물 기하 구조와 같은 다양한 입력 특징을 학습함으로써 전파의 세기와 특성을 예측할 수 있다. 이러한 특징들은 전파의 반사, 굴절, 산란, 흡수 등을 포함한 실내 전파의 동적인 변화를 반영하며, CNN을 통해 효과적으로 학습되어 정확한 전계강도 예측을 가능하게 한다. CNN의 합성곱 계층은 입력 데이터의 지역적 특징을 감지하고, 감지된 특징은 실내 전파의 특성을 출력할 수 있다. 예를 들어, 벽 뒤의 신호 감쇠, 굴절 지점의 신호 반사 등의 패턴을 학습할 수 있으며, CNN의 풀링 계층은 출력된 패턴을 요약하고, 더 높은 수준의 특징을 추출하여 실내 전파의 전반적인 특징을 이해하는 데 도움을 준다.
그림 1은 CNN 모델 구조를 시각화한 것이며, feature extraction, fully connected layer, regression 단계로 구성되어 있다. Feature extraction 단계에서는 각 레이어의 필터가 표시된다. 필터는 각각 f1 × f2 × f3 형태로 표시되어 있으며, 여기서 f1, f2는 데이터의 크기를 의미하고, f3는 각 계층에서 사용되는 필터의 개수를 나타낸다. Fully connected layer의 크기는 모델의 출력을 생성하는 데 사용되는 연결된 뉴런의 수를 의미한다. Regression 단계는 예측값을 생성하는 마지막 단계이다.
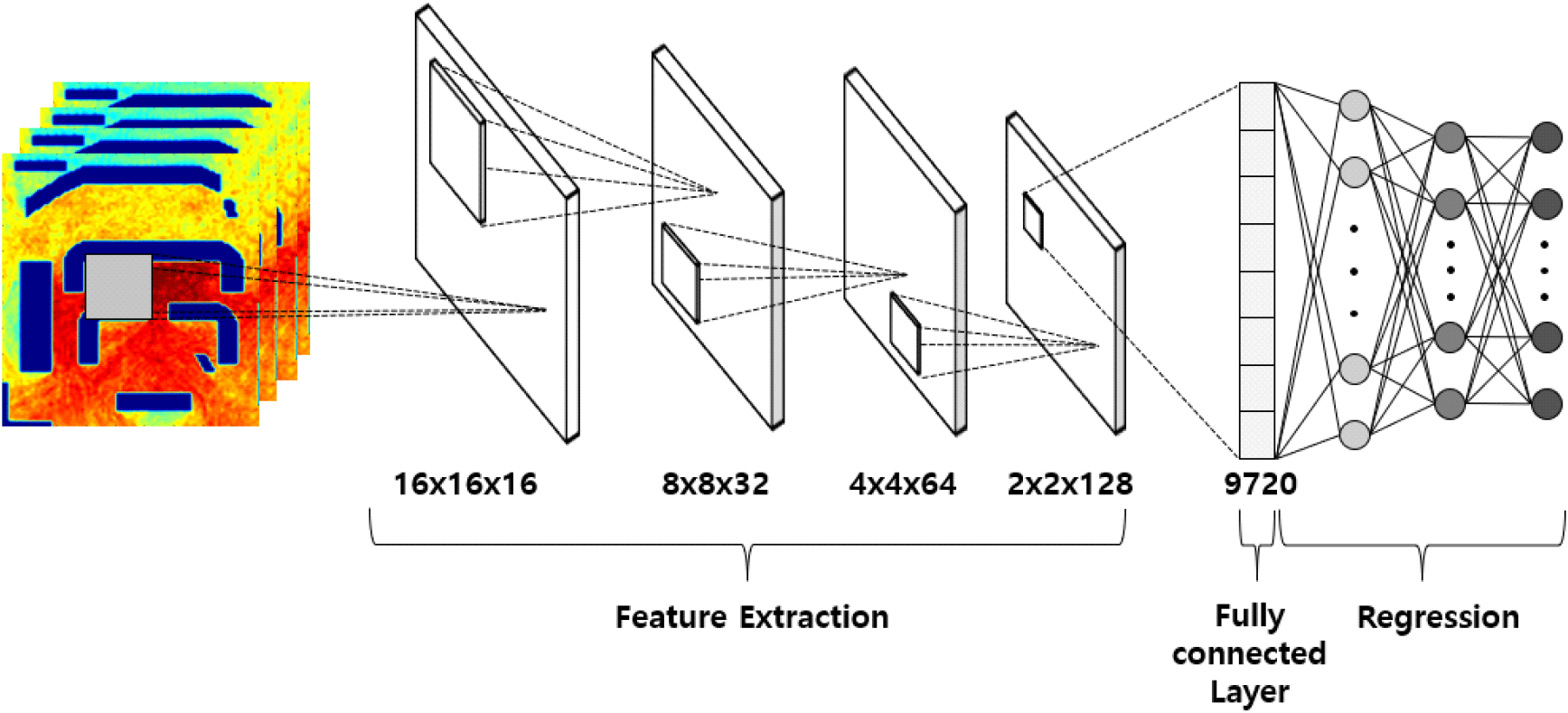
표 1에서 각 레이어에서 사용되는 필터의 크기와 fully connected layer의 크기를 요약하였다. 필터의 크기는 각 레이어에서 사용되는 필터의 크기와 해당 필터를 convolution, Average Pooling으로 학습을 진행한다. Average Pooling은 주변 픽셀들의 평균값을 계산하여 전체적인 신호의 패턴을 더 잘 반영할 수 있다[8]. 이는 실내 환경에서 다양한 장애물과 반사로 인해 신호 강도가 급변하는 경우가 많기 때문에, 평균값을 사용하여 신호의 전반적인 특성을 더 안정적으로 파악할 수 있도록 도와준다.
표 2에서 CNN 모델의 학습 과정에서 사용되는 주요 파라미터들을 요약하였다. batch_size, activation, optimizer, learning_rate, epoch, loss function, test/val 비율 파라미터가 포함되어 있으며, 각 파라미터는 모델의 학습 성능과 결과에 큰 영향을 미치므로 파라미터를 적절하게 조정하는 것이 중요하다.
| Parameter | Value |
|---|---|
| Batch_size | 16 |
| Activation | ReLu |
| Optimizer | Adam |
| Learning_rate | 0.001 |
| Epoch | 200 |
| Loss function | Mean square error |
| Test/val ratio | 75% / 25% |
CNN 학습 과정의 목표는 손실(loss)을 최소화하고 정확도를 향상시키는 것이다. 이를 위해, 모델의 파라미터를 조정하여 예측값과 출력값 사이의 오차를 줄인다. 손실함수(loss function)는 오차를 측정하는 데 사용되며, 경사하강법을 통해 가중치를 업데이트한다.
식 (1)은 가중치 업데이트 과정을 나타내며, wnew 는 업데이트된 가중치, wold 는 현재의 가중치, η는 학습률, ▿wL(w)는 손실함수에 대한 가중치의 기울기로, 모델이 오차를 줄이는 방향으로 학습하도록 돕는다. 이 과정을 통해 모델은 손실함수의 값을 최소화하며, 예측이 실제 값에 점점 더 가까워지도록 개선된다.
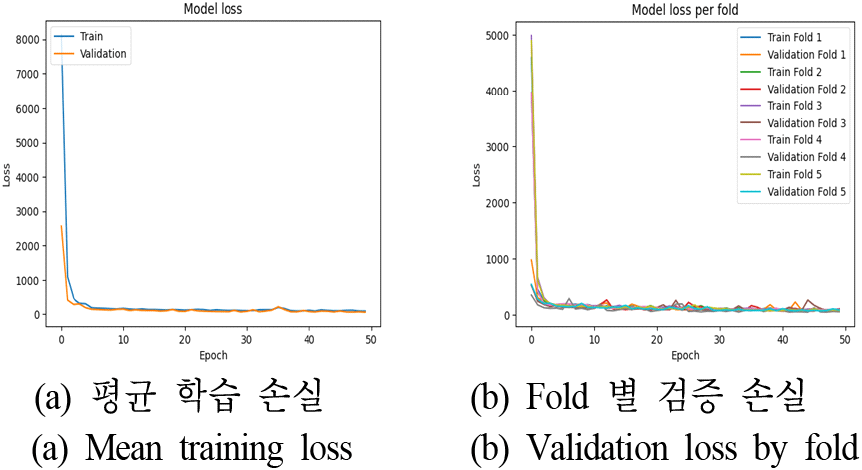
본 연구에서는 CNN 모델의 일반화 성능을 평가하기 위해 k-fold 교차 검증을 사용하였다. k-fold 교차 검증은 데이터를 5개의 폴드로 나누어, 각 폴드가 한 번씩 검증 데이터로 사용되고, 나머지 k−1개의 폴드는 학습 데이터로 사용되는 방식이다. 이를 통해 모델이 특정 데이터셋에 과적합되지 않고, 전체 데이터에 대해 일관된 성능을 유지하는지 평가할 수 있다[9].
그림 2는 k-fold 교차 검증을 통해 얻은 학습 및 검증 손실을 나타낸 것이다. 그림 2(a)는 전체 학습 및 검증 손실을, 그림 2(b)는 각 폴드별 손실을 보여준다. 이를 통해 모델의 성능이 각 폴드에서 일관되게 유지됨을 확인할 수 있다. 이를 통해 CNN 모델의 일반화 성능을 신뢰성 있게 평가할 수 있다.
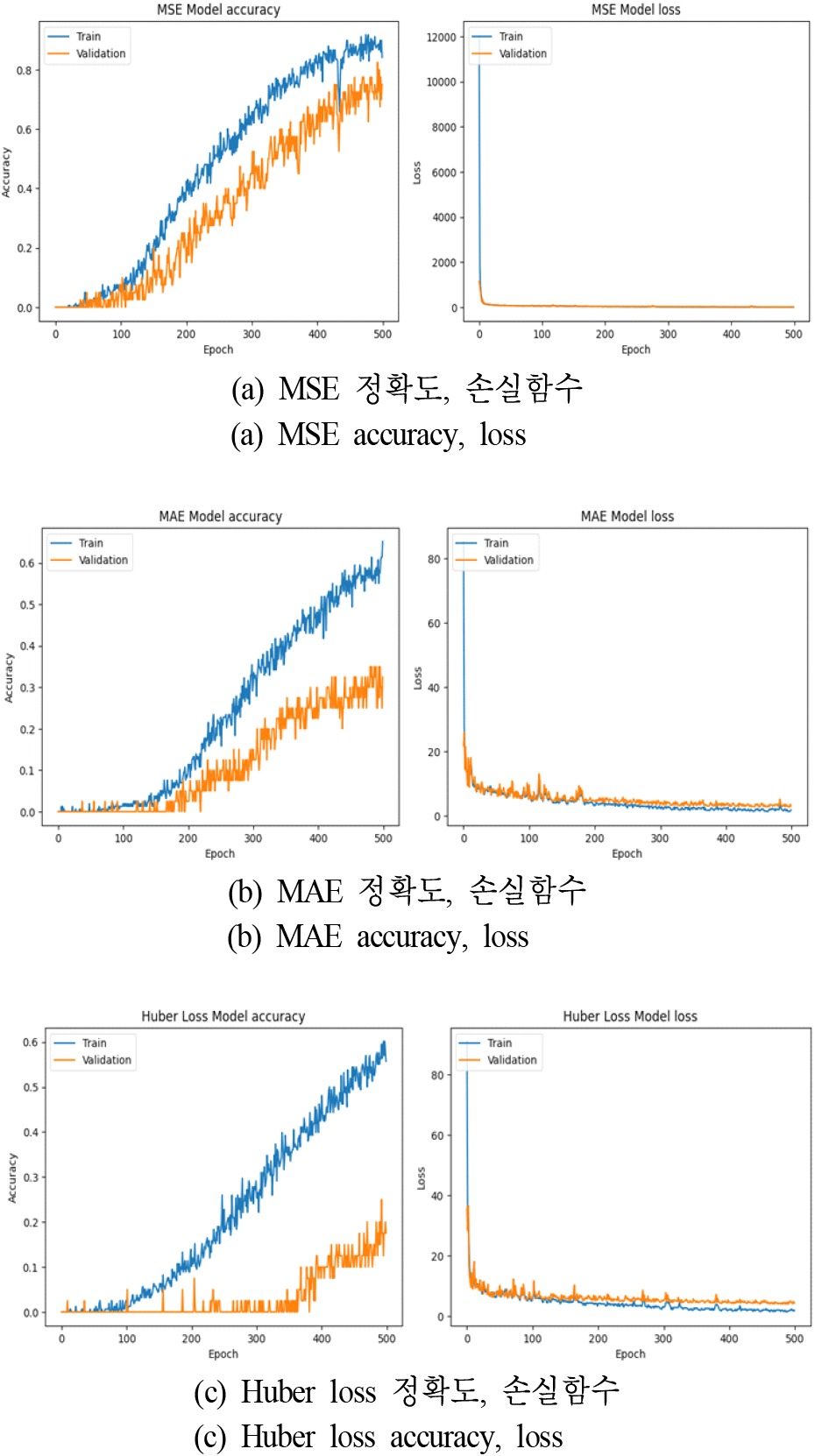
본 연구에서 ablation study를 위해 손실함수를 제외하고 표 2의 CNN 모델 파라미터를 사용하였다. Ablation study란 특정 변수를 변경하여 모델의 성능에 미치는 영향을 분석하는 기법을 의미한다. 이를 통해 각 특정 변수가 모델에 어떤 영향을 미치는지 평가할 수 있다[10].
그림 3은 MSE, MAE, Huber Loss 함수를 사용했을 때 학습 데이터셋과 검증 데이터셋에 대한 정확도와 손실의 변화를 보여준다. 결과적으로 손실 함수의 선택이 CNN 모델의 학습 및 출력 성능에 영향을 미침을 확인하였다. 본 논문에서는 그림 3(a)의 MSE를 사용하였으며, 학습 횟수가 증가할 때 overfitting이 발생하는 구간을 고려하여 논문에서 사용한 학습 횟수는 200회로 사용하였다.
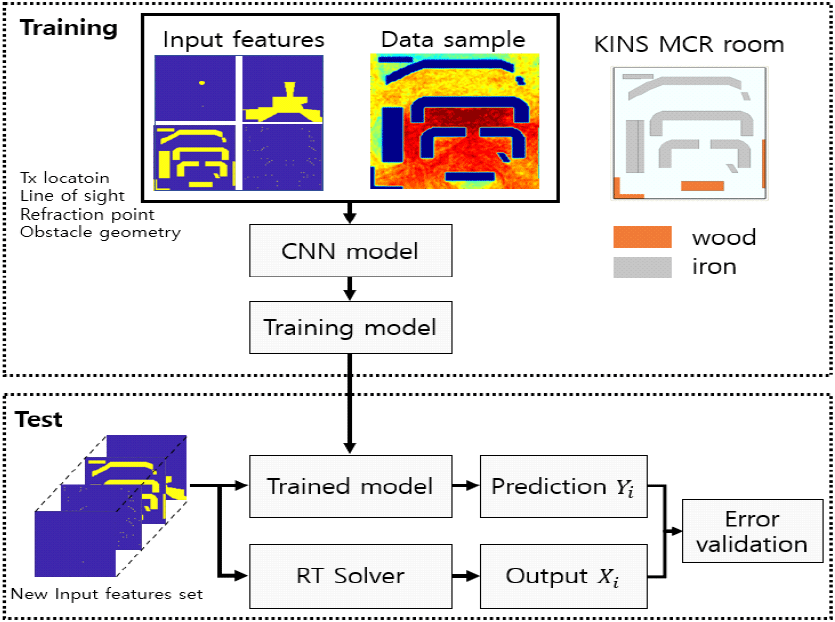
본 논문은 RT simulator에서 제공된 출력값을 기반으로 CNN을 활용하여 전계를 예측한다.
우선 RT simulator를 사용하여 KINS 시뮬레이터를 설계하였다. 다음으로 MATLAB을 활용하여 KINS 시뮬레이터 주 제어실을 설계하였다. 사용될 데이터는 송신안테나 위치, line of sight, 장애물 구조, 굴절지점이며, 송신안테나의 위치는 ‘1’로 표시하였으며, 자유 공간은 ‘0’으로 표시하여 데이터화 하였다. 각 입력 특징도 송신안테나의 위치처럼 데이터화 하였으며, 이 데이터들은 RT simulator를 통해 얻은 송신안테나의 전계 데이터와 일치시켜 CNN 모델의 입력으로 사용되어 학습에 활용되었다.
기존 연구[5]와 비교하여 본 연구에서는 Ray tracing 시뮬레이터를 사용하여 전계 분포 데이터를 수집하였으며, 기존 연구에서는 SBR(shooting and bouncing ray) 방법을 사용하였다. 또한, 본 연구는 주 제어실 내 다양한 송신안테나 위치에 대한 예측 성능을 평가하여 특정 환경에서의 정확한 전계 예측을 목표로 하고 있다. 반면, 기존 연구에서는 새로운 지오메트리, 송․수신 위치 및 주파수에 대한 일반화 성능을 평가하여 보다 광범위한 환경에서의 활용 가능성을 탐구하였다. 마지막으로, 본 연구에서는 배치 크기, 활성화 함수, 최적화 알고리즘 등의 다양한 하이퍼 파라미터를 실험하여 최적화하였으며, 이를 통해 모델의 예측 정확도를 높였다. 기존 연구에서는 물리 기반의 입력 파라미터와 비용 함수를 설정하여 네트워크가 기본적이고 복잡한 전파 메커니즘을 학습하도록 하였다.
CNN을 이용하여 전계강도를 예측하기 위해서는 그림2와 같은 입력값들이 필요하다. 그림 4(a)는 송신안테나의 위치를 나타내며, 전파의 초기 방향을 결정한다. 그림 4(b)는 송신안테나와 수신 안테나 사이에 직접적인 전파 경로의 여부를 나타낸다. 전파는 다중으로 퍼지는 경향이 있으므로 전파의 세기와 품질에 영향을 미치는 중요한 요소 중 하나이며, line of sight가 입력 특징으로 제공되지 않을 경우 전계 수치가 전체적으로 상승하여 기존 시뮬레이션 대비 10 % 이상의 오차상승을 보임을 확인하였다. 그림 4(c)는 전파가 장애물의 모서리를 따라 굴절되는 지점을 가리키며, 전파의 방향과 세기를 변화시켜 전파의 경로와 특성에 영향을 미친다. 그림 4(d)는 실내 구조물의 형태와 위치를 나타내며, 전파의 반사, 굴절, 산란, 흡수 등의 현상을 일으키고, 전파의 분포와 특성에 영향을 미치게 된다. 이 네 가지 특징은 실내 전파의 패턴과 특성을 감지하고 학습하는 과정에서 중요한 역할을 한다. 그림 3에서 이 특징들은 CNN 모델의 학습 및 테스트 과정에서 사용된다.

그림 5는 CNN 모델의 학습 및 테스트 과정을 보여준다. 학습 단계에서는 그림 2의 입력 특징과 구조가 CNN 모델에 입력되며, 이는 송신안테나 위치, line of sight, 장애물 구조, 굴절지점으로 구성된다. 입력 데이터는 (W × H × N)구조이며, W는 필터의 너비, H는 높이, N은 사용된 샘플 수로 구성된다. 송신안테나 위치는 RT 시뮬레이터를 사용하여 무작위로 배치하였다. 테스트 단계에서는 CNN 모델의 성능을 평가하기 위해 90×108×1 형태의 기존에 학습시키지 않은 입력 특징 세트를 모델에 입력하여 예측값 (Yi)을 출력한다. 입력 특징 세트는 송신안테나 위치, line of sight가 변수로 입력되고, 굴절지점과 장애물 구조는 고정된 값으로 입력된다. 새 입력 특징의 출력된 예측값은 RT 시뮬레이터로 계산된 출력값 (Xi)과 비교되며, 오차 검증 결과에 따라 모델 파라미터를 조정하여 모델을 개선할 수 있다. 이 과정은 CNN 모델이 실제 환경에서 전파를 예측할 때 얼마나 효과적인지 평가할 때 활용된다.
Ⅲ. 모의실험 및 검증
본 연구에서는 원자력 발전소의 배제구역(exclusion zone)을 모방한 한국원자력안전기술원(KINS) 시뮬레이터 주 제어실을 활용하였다. 주 제어실은 가로 15 m, 세로 18 m의 크기를 가지며, 그림 6과 같이 목재와 철제로 구성된 내부 구조를 통해 실제 원전환경을 반영하였다. 송신안테나와 수신안테나는 모두 1 m 높이에 위치하며, 송신안테나는 무작위로, 수신안테나는 90×108 배열로 배치하였다. 사용된 다이폴 안테나는 수평면에서 무지향성 방사 패턴을 가지며, 안테나 이득은 2.5 dBi이다.

입력 샘플은 90×108×100 형태로 100개의 샘플이 제공된다. 설계된 구조에 대해 RT 시뮬레이터로는 Wireless Insite를 사용하였다. CNN 모델은 Python과 Matlab을 기반으로 구축하였다. Python은 데이터 처리와 모델 학습을 위한 라이브러리인 TensorFlow와 Keras를 사용하였으며, Matlab은 데이터 분석과 시각화를 위해 사용하였다. CNN 모의실험환경을 표 3에 정리하였다.
RT 시뮬레이터를 사용한 전계 출력은 상당한 시간이 소요되지만, CNN은 구조물에 대한 정보를 이미지 형태로 처리하므로, 전계 출력에 비교적 적은 시간이 소요된다. 실제 원전환경에서의 전계 강도를 모의시험을 통해 재현하였고, CNN 모델 검증을 통해 모델의 예측 능력을 검증하고 최적화하였다. 그림 7은 송신안테나 위치 변화에 따른 안테나 위치이다. 기존에 학습시키지 않은 송신안테나 위치에 대한 네 가지 케이스에 대하여 CNN 모델로부터 출력값을 구하였다. CNN 모델로부터 얻은 값을 RT 시뮬레이터와의 값과 비교하기 위하여 식 (2)와 같은 NMSE(normalized mean square error)를 구하였다.
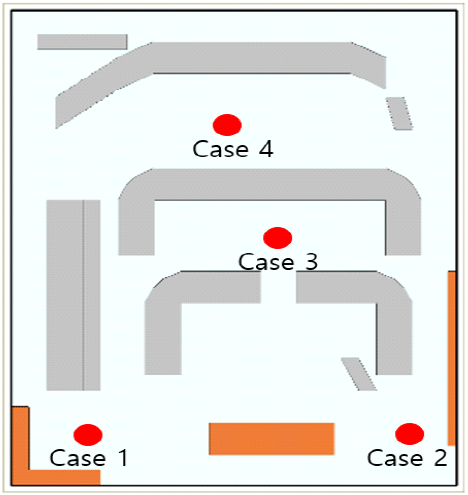
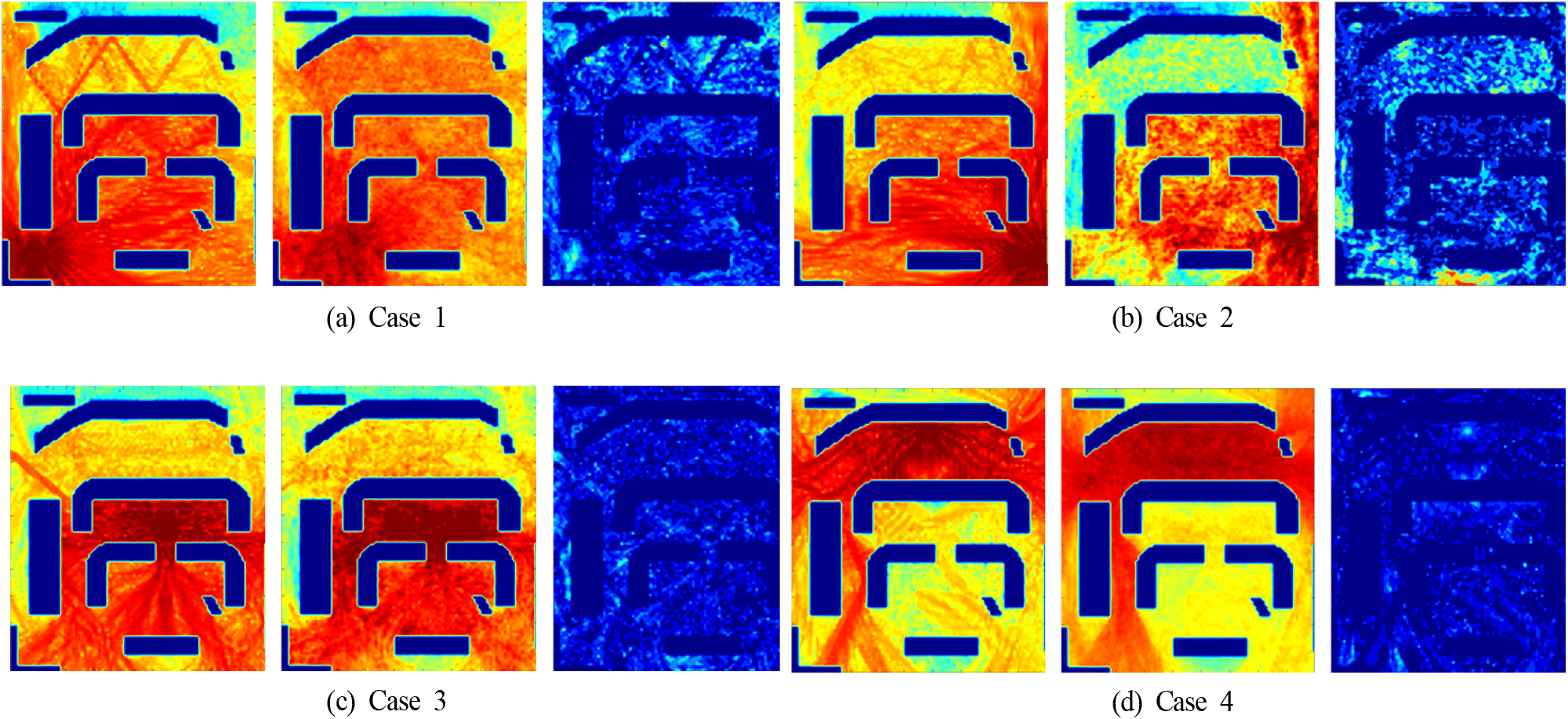
실험 결과로 송신안테나 100개의 데이터를 Wireless Insite를 사용하여 출력하는 데 약 8시간이 소요되었으나, CNN 모델을 사용하여 동일한 데이터를 출력하는 데는 약 30초가 소요되었다. 이는 CNN 모델이 전계 예측을 매우 빠르고 효율적으로 수행할 수 있음을 보여준다. 각 케이스에 대한 좌표와 NMSE 평균오차율은 표 4에 정리하여 제시하였다. 그림 8은 송신안테나 위치 변화에 따른 각 케이스별 오차를 보여주며, 각 순서는 RT 시뮬레이터 출력값, CNN 예측값, 오차를 나타낸다. 이 값들은 dBμV/m으로 표현하였다. 그림 8(a)~그림 8(d)는 5% 미만의 오차율을 보이고, 가장 큰 오차를 보이는 그림 6(b)는 안테나 위치 근방의 기존에 학습시킨 데이터가 적어 오차율이 큰 것으로 판단된다. 오차율을 줄이고 정확한 결과를 출력하는 방법으로는 제공될 학습 데이터 샘플의 수를 늘리거나, CNN 최적화 파라미터를 변경하여 출력값과 예측값이 가장 유사한 결과가 나오도록 파라미터를 변경하는 방법이 있다.
| Location (m) | Average NMSE rate (%) | |
|---|---|---|
| Case 1 | 2, 2 | 1.0 |
| Case 2 | 14, 2 | 2.7 |
| Case 3 | 9, 9 | 0.7 |
| Case 4 | 8, 15 | 0.4 |
FSV(feature selective validation) 알고리즘은 전자기학적 데이터의 비교와 검증을 위해 개발된 통계적 방법이다[11]. 이 알고리즘은 두 데이터 세트 사이의 유사성을 측정하는데 사용되며, ADM(average difference measure), FDM (feature difference measure), GDM(global difference measure) 세 가지의 주요 지표를 사용하여 유사성을 평가한다.
ADM은 데이터의 평균적인 차이를 측정하며, 값이 작을수록 데이터 세트의 진폭 유사도가 높다. 식 (3)로 계산되며, N은 데이터 샘플 수, Xi는 출력값, Yi는 예측값이다.
FDM은 데이터의 형태와 패턴의 차이를 측정하며, 값이 작을수록 데이터 세트의 유사도가 높다. 식 (4)으로 계산되며, σX는 X의 표준편차, σY는 Y의 표준편차이다.
GDM은 데이터의 전체적인 유사도를 측정하며, 식 (5)로 계산된다. ADM과 FDM으로 계산되며, GDM이 작을수록 두 데이터 세트의 유사도가 높음을 의미한다.
표 5는 GDM 값을 기준으로 두 데이터 세트의 유사성을 평가하는 기준과 결과이며, 표를 통해 두 데이터 세트의 유사도가 높음을 확인하였다.
| FSV value GDM | FSV criteria | GDM score |
|---|---|---|
| GDM≤0.1 | Excellent | 4,892 |
| 0.1<GDM≤0.2 | Very good | 2,826 |
| 0.2<GDM≤0.4 | Good | 1,670 |
| 0.4<GDM≤0.8 | Fair | 242 |
| 0.8<GDM≤1.6 | Poor | 71 |
| 1.6<GDM | Very poor | 19 |





