
Ⅰ. 서 론
딥러닝은 데이터 기반의 연구로서 의미있는 연구를 수행하기 위해서는 양질의 데이터셋이 필수적이다. 하지만 SAR(synthetic aperture radar) 영상은 광학 영상에 비해 육안 분석이 어렵고 데이터 획득도 쉽지 않아 딥러닝 모델을 학습하기 위한 고품질의 데이터셋이 부족한 현황이다. 특히 탐지식별의 경우 비교적 라벨링이 용이한 해상 선박 데이터셋이 대부분이다. 본 연구에서는 지상 군사 표적에 대한 딥러닝 탐지식별 연구를 수행하기 위해 미국방부에서 탱크, 수송차, 로켓 런처, 불도저, 트럭 등 10개 클래스에 대해 구축한 MSTAR(moving and stationary target acquisition and recognition)[1] 식별 데이터셋을 기반으로 새로운 탐지 데이터셋을 구축하였다. 이후 이를 검증하고 SAR 영상에서의 지상 표적 탐지 네트워크의 전반적인 성능을 확인하기 위해 다양한 모델들에 대한 벤치마크를 수행하였다. 또한 향후 실제 항공 SAR 영상에서의 활용을 고려하여 항공기 요동 및 시스템 내부 오차 등에 의해 발생할 수 있는 위상 오차에 따른 탐지 성능 변화 경향성을 분석하고자 하였다.
본 논문에서는 먼저 MSTAR 데이터셋의 합성을 통해 탐지 데이터셋을 구축한 방법에 대해 서술하였다. 배경과 표적으로 구성되는 탐지 데이터셋의 특성을 고려하여 다양한 표적 및 배경을 포함하며 둘 사이의 이질감을 줄이는 것을 목표로 하였다. 그렇게 구축된 데이터셋을 검증하기 위해 탐지 모델 학습 및 평가를 통한 벤치마크를 수행하였다. 가장 기본적인 탐지 모델부터 속도는 느리지만 정확도가 높은 2-stage 모델과 정확도는 떨어지지만 연산 효율이 좋은 1-stage 모델을 모두 포함하여 다양한 네트워크를 활용해 성능을 분석하였다. 추가적으로 정제된 데이터셋으로 학습 및 평가를 수행한 벤치마크 성능을 베이스라인으로 삼고 평가 영상에 위상 오차가 추가될 경우 탐지 성능이 열화되는 경향성을 확인하였다. 위상 오차의 성분 및 정도에 따른 성능 변화 뿐 아니라 서로 다른 탐지 모델 간의 성능 변화 차이 여부도 분석하였다. 해당 결과를 바탕으로 기구축 모델을 활용하여 실제 SAR 영상에서 지상 표적 탐지를 수행할 경우 평가 영상에서 허용 가능한 오차의 범위를 정의할 수 있었고 향후 SAR 영상 획득 실험시 항공기 요동 및 시스템 내부 오차 제어를 위한 자료로 활용할 수 있을 것으로 기대한다.
Ⅱ. SAR 탐지식별 데이터셋 구축
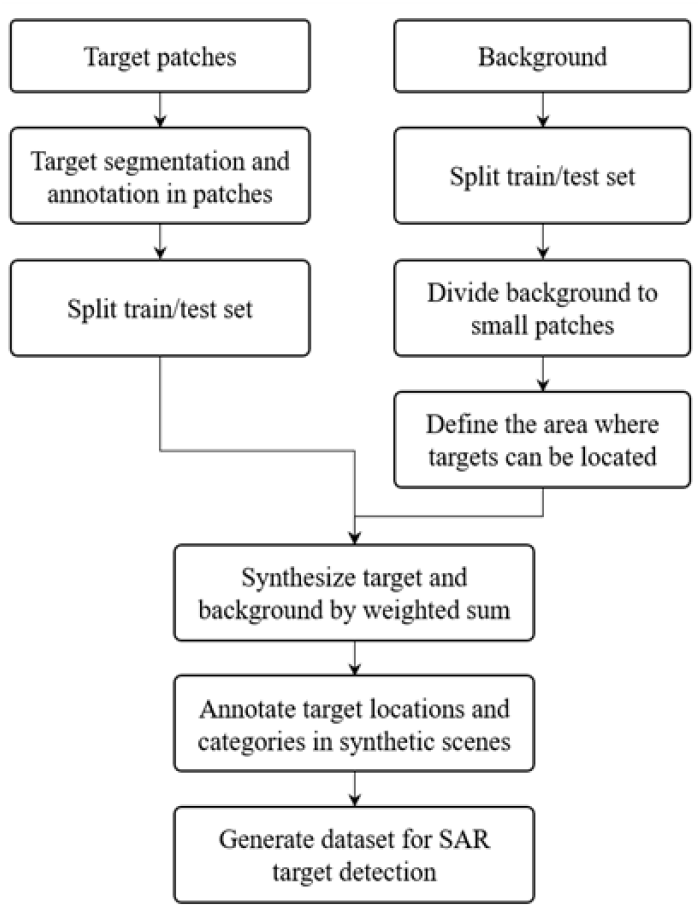
데이터 기반의 딥러닝 네트워크 연구를 수행하기 위해서는 양질의 데이터셋을 구축하는 것이 가장 중요한 부분이라고 볼 수 있다. 본 연구에서는 MSTAR 데이터셋을 기반으로 표적과 배경 영상을 합성하여 SAR 영상에서의 지상 표적 탐지 데이터셋을 구축하고자 하였다. 이번 장에서는 데이터셋을 생성하는 방법을 서술하고자 한다.
배경 영상에 표적을 합성하기 위해서 가장 먼저 표적 패치 영상에서 표적에 해당하는 부분을 분할하여 그에 대한 라벨 데이터를 생성하였다. 패치 영상 내 상위 3 % 밝기 영역은 표적으로, 하위 25 % 밝기 영역은 그림자로 정의[2]하여 표적과 그림자의 위치에 대한 정보 및 표적의 클래스 등을 포함하고자 하였다. 이 때 MSTAR 데이터셋에 포함된 표적의 azimuth 각도를 기반으로 표적의 방향성까지 정의할 수 있었다. 영상에서 보여지는 방향이 유사하더라도 azimuth 각도에 따라 표적의 바운딩 박스 포인트 순서를 다르게 부여해 박스의 방향성을 지정할 수 있다. 그에 따라 표적의 azimuth 각도와 rotated 바운딩 박스의 각도가 유사하도록 라벨링 정보를 저장하였다.
다음으로 표적 영상과 배경 영상을 각각 학습과 평가셋의 3 대 1 비율로 분리하였다. 표적 영상의 경우 SOC (standard operating condition) 환경에서의 범용적인 활용 및 충분한 영상 수를 확보하기 위해 고각 15, 16, 17도의 표적을 사용하였다. 배경 영상으로는 MSTAR 데이터셋에 포함되어 있는 클러터 영상을 활용하였다. 다양한 배경을 포함하는 양질의 데이터셋을 생성하기 위해 오버랩을 포함하여 배경 영상을 약 500×500의 크기로 패치화하였다. 최종적으로 사용한 표적 및 배경 영상의 개수는 표 1과 같다.
| Train | Test | |
|---|---|---|
| Target patches | 4,742 | 1,577 |
| Background | 1,875 | 625 |
| Synthesized targets | 9,003 | 2,890 |
합성에 사용할 표적 영상 및 배경 영상을 준비한 후 배경 영상 내 표적이 위치할 수 있는 영역을 정의하고자 하였다. 빌딩이나 숲 등 표적이 위치할 수 없는 영역을 피하기 위해 배경 영상에서 일정 영역에 대해 반사계수의 표준편차가 임계치 이하인 영역으로 제한하였다. 해당 영역에서 무작위로 표적의 위치 선정 후 거리가 너무 가까운 경우는 제거하여 표적이 겹쳐서 나타나지 않도록 하였다(그림 1).
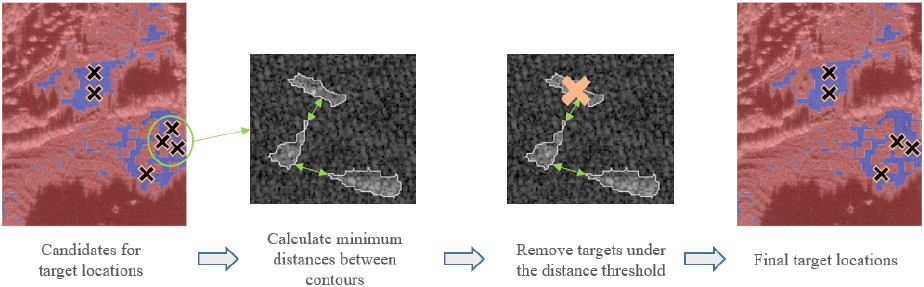
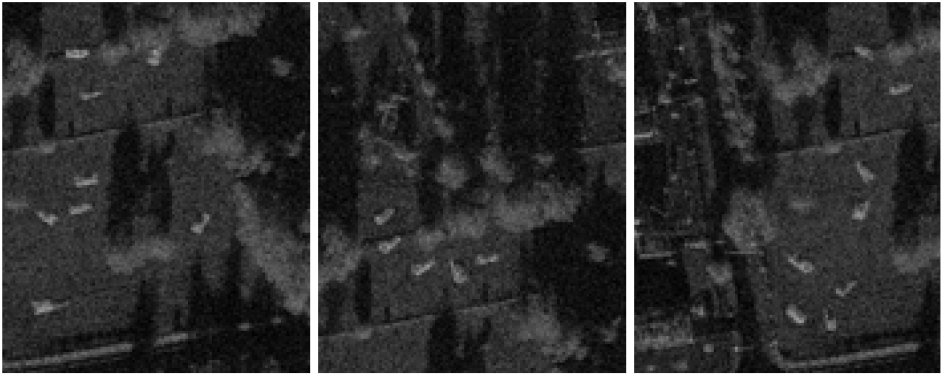
선정된 표적 위치를 기반으로 표적 패치와 배경 영상의 학습셋과 평가셋에 대해 각각 랜덤하게 합성을 수행하고 어노테이션을 생성하였다. 이 때 배경 영상과 분할된 표적 사이의 이질감을 줄이기 위해 표적 윤곽선에 대한 거리 함수를 기반으로 가중치 합을 적용하여 영상을 합성하였다. 또한 표적과 배경 영상 모두 원본 complex 형태를 사용하며 합성된 결과 역시 complex 형태로 저장하여 SAR 영상의 특성을 최대한 살리고자 하였다. 이후 합성 영상을 탐지식별 모델에 입력으로 넣을 때 정규화 등의 전처리 과정을 적용하였다. 그렇게 합성된 영상을 바탕으로 각 배경 영상에서 표적의 위치와 클래스 등을 포함하는 탐지식별 데이터셋을 구축하였고 그림 2에서 데이터셋 예시를 확인할 수 있다. 그림 3은 SAR 영상에 대한 탐지식별 데이터셋을 구축한 과정에 대한 전체적인 순서도를 보여준다.
Ⅲ. SAR 탐지식별 모델 벤치마크
구축한 데이터셋을 바탕으로 다양한 탐지 모델에 대한 성능 벤치마크를 수행하여 데이터셋을 검증하고 SAR 탐지 모델에 대한 전반적인 성능을 확인하였다. 딥러닝 탐지 모델은 크게 표적의 위치와 클래스를 동시에 예측하여 속도는 빠르지만 정확도는 조금 떨어지는 1-stage 탐지기와 표적의 위치에 대한 정보를 먼저 추출 후, 정확한 박스와 클래스 정보를 추정하여 정확도는 향상되지만 속도가 느린 2-stage 탐지기로 구분된다. 성능과 속도 및 데이터셋의 특성을 모두 고려하며 다양한 탐지기를 활용하여 벤치마크를 수행하고자 하였다.
탐지 모델을 평가하기 위한 지표는 다음과 같다. 정답 중 얼마나 많은 객체를 탐지했는가에 대한 recall과 탐지한 결과 중 얼마나 정답이 많이 포함되었는가에 대한 precision으로 구분할 수 있다. 탐지 신뢰도에 대한 기준값에 따라 trade-off의 관계를 가지며 그에 따른 그래프 면적인 AP(average precision)와 클래스별 AP의 평균을 의미하는 mAP(mean AP) 등이 가장 널리 사용되는 탐지 모델에 대한 평가 지표이다. 탐지 성능에 대한 지표 외에도 모델의 연산 속도를 보여줄 수 있는 FPS(frame per seconds) 및 연산에 필요한 메모리 등도 함께 분석하였다.
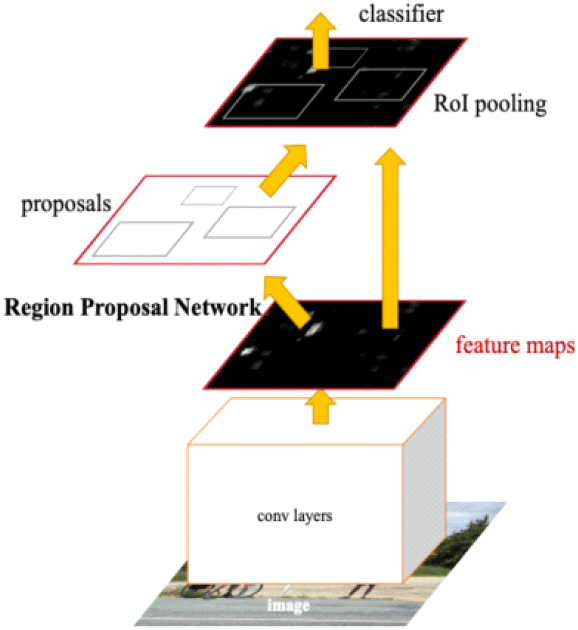
Faster RCNN은 딥러닝 탐지 네트워크의 가장 기본이 되는 모델 중 하나이다. 입력 영상으로부터 특징맵 추출 후 RPN(region proposal network)에서 객체의 위치에 해당하는 region proposal을 먼저 산출한다. 이후 특징맵과 융합하여 RoI(region of interest) pooling을 수행해 고정된 크기의 특징맵을 얻는다. 그렇게 고정된 크기의 특징맵으로부터 객체의 정확한 위치와 클래스를 예측한다. 모든 레이어를 CNN (convolution neural network) 기반으로 구성해 연산 효율을 높이며 end-to-end 학습이 가능해 딥러닝 탐지 네트워크 발전의 초석이 된 모델이다(그림 4).
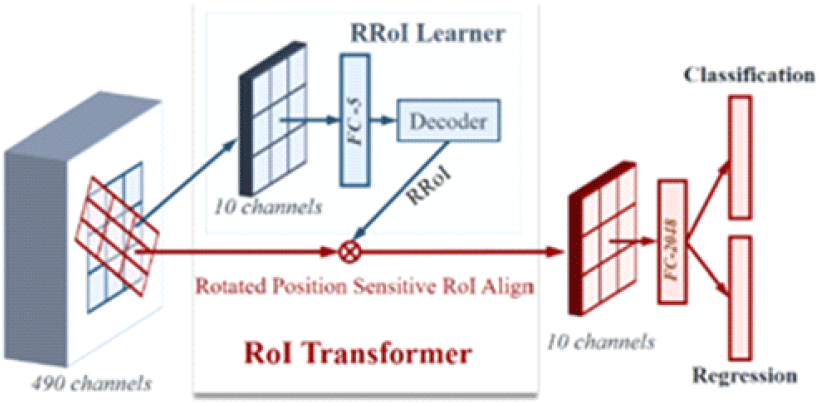
Horizontal box에 대한 수평 방향의 RoI를 Rotated RoI로 변환하는 과정과 그 때의 파라미터를 학습하는 방법이다. Hbox(horizontal box) 탐지에서 rbox(rotated box)로 넘어가는 과정에서 발생하는 문제를 해결하며 성능과 연산 효율을 향상시켰다. 또한 rbox를 활용한 다양한 탐지기에 적용 가능하다는 장점이 있다. RRoI learner에서는 특징맵의 HRoI에서 RRoI로의 변환 과정을 학습하며 RoI와 객체의 부정합을 완화하고 rbox 탐지에 따르는 연산 효율 감소 문제를 해결했다. RRoI warping 모듈에서는 공간 불변 특징을 추출하여 성능 및 연산 효율성을 향상시켰다(그림 5 및 그림 6).
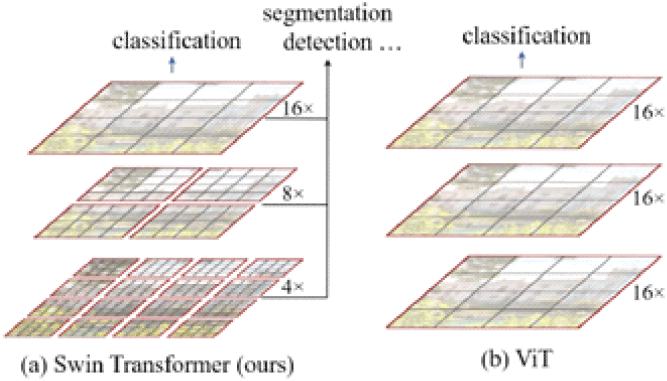
이 때 탐지기 이전에 영상의 특징을 추출하는 backbone을 가장 기본적인 ResNet[5]외에 Swin-transformer[6]를 추가적으로 적용해 보았다. Transformer는 자연어 모델에서 시작된 네트워크로 self-attention 기법을 적용해 문장 속에서 중요 정보에 집중하며 불필요한 정보는 제외하고 학습하는 방법이다. Swin-transformer는 이를 비전 분야에 적용하며 계층 구조를 활용해 다양한 스케일에 대한 학습까지 가능하도록 하여 식별, 탐지, 분할 등 다양한 비전 모델에서 좋은 성능을 도출하는 backbone이다.
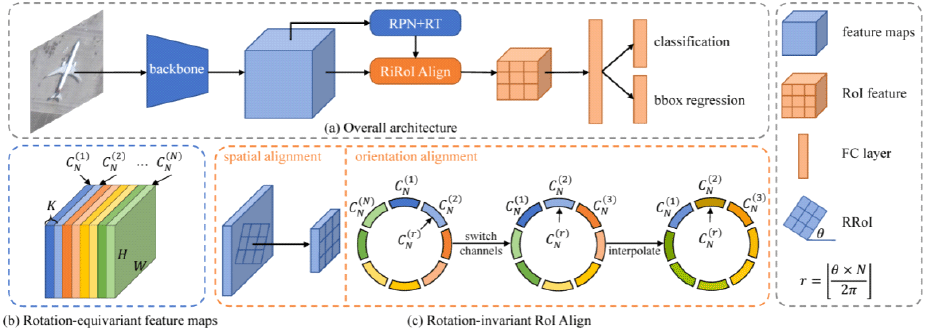
ReDet(rotation-equivariant detector)는 항공 및 위성 영상에서의 객체 탐지를 위해 고안된 모델 중 하나로 정확한 방향 정보를 예측하는 것에 집중한 모델이다. 회전 등분산과 회전 불변성을 명시적으로 인코딩하기 위해 회전 등변 네트워크를 탐지기에 통합하여 회전 등변 특징을 추출한다. 결과적으로 기존 모델들에 비해 더 정확한 rotated box를 예측할 수 있다(그림 7).
딥러닝 탐지 네트워크에서 가장 연산이 복잡한 부분 중 하나는 객체의 위치를 찾기 위한 anchor box에 대한 계산이다. FCOS(fully convolutional one-stage object detection)는 anchor box를 제거한 anchor-free 기법의 대표적인 방법으로 객체의 중심점으로부터 바운딩 박스의 경계까지의 거리를 예측해 객체의 위치를 추정한다. Anchor box에 필요한 하이퍼 파라미터 튜닝 및 복잡한 계산 과정 등이 생략되기 때문에 연산 속도가 크게 증가됨과 동시에 기존의 다른 탐지 모델에 비해 좋은 성능을 보였다(그림 8).

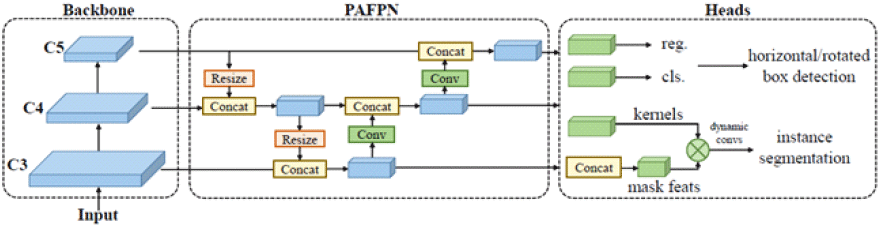
탐지기의 연산 효율 및 속도를 고려하여 1-stage YOLO 기반 모델도 적용해 보았다. RTMDet(real-time models for object detection)는 YOLO 기반 네트워크 중 SOTA(stage-of-the-art) 성능을 달성하고 있는 모델로, large kernel과 depth-wise convolution을 사용하여 네트워크가 처리 가능한 영역의 크기를 넓힘과 동시에 학습 cost 및 에러를 감소시킨다. 또한 라벨의 matching cost 계산 과정에서 소프트 라벨을 사용해 매칭의 불안정성 및 노이즈를 완화해 정확도를 향상시켰다(그림 9).
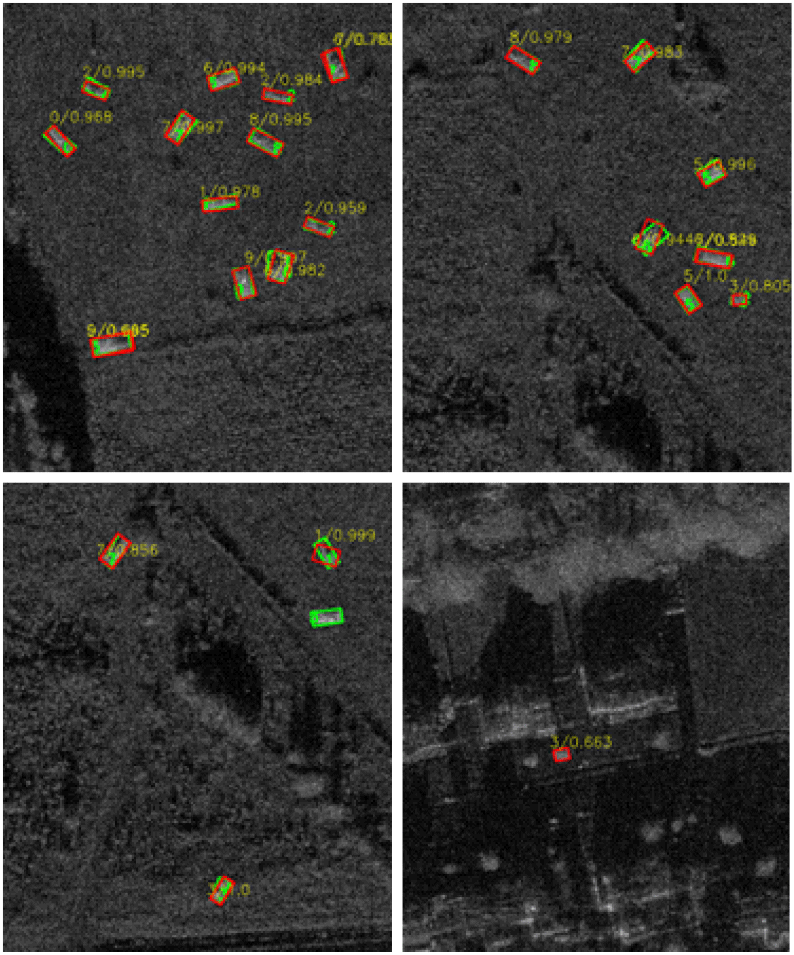
다양한 탐지 모델을 활용해 구축한 데이터셋을 학습하고 평가한 벤치마크 결과는 표 2와 같다. 전반적으로 mAP 0.8 이상의 좋은 성능을 도출하는 것을 보아 지상 군사표적에 대한 탐지 데이터셋 구축이 어느정도 검증된 것으로 볼 수 있다. 10개 클래스에 대한 mAP 및 recall값을 봤을 때 RoI transformer(swin transformer backbone)와 RTMDet가 각각 mAP 0.89, 0.87 정도로 가장 좋은 성능을 보이는 것을 확인하였다. 그림 10은 RoI transformer의 추론 결과를 시각화한 것이며 초록색 박스가 정답지, 빨간색 박스가 추론 결과이다. 비교적 높은 신뢰도를 보이며 탐지가 수행된 것을 볼 수 있다.
Ⅳ. 위상 오차에 따른 영상 및 탐지 성능 변화 분석
SAR 시스템을 항공기에 탑재하여 영상을 촬영할 경우 항공기 요동 및 시스템 내부 오차 등에 의해 위상 오차가 발생할 수 있다. MSTAR 데이터셋으로 학습한 모델을 이용해 실제 항공기 SAR 영상에서 탐지식별 추론을 수행하고자 할 경우 이러한 오차에 의한 성능 저하가 발생할 수 있는 것이다[10]. 따라서 위상 오차에 의한 영상의 변화 양상 및 탐지 모델 성능의 열화를 분석하고 결과적으로 허용 가능한 오차의 범위를 확인하고자 하였다.
영상에 위상 오차를 추가하기 위해서는 시간 도메인의 신호를 주파수 도메인으로 변환하여 적용할 수 있다. 이는 탐지식별 데이터셋을 구축하기 위해 영상을 합성할 당시 complex 원시 데이터를 그대로 사용하였기 때문에 가능하다. 먼저, 시간 도메인의 SAR 영상에 푸리에 변환을 적용하여 주파수 도메인으로 변환한다. 이후 임의의 위상 오차를 정의하고 주파수 도메인의 신호에 해당 오차를 곱해준다. 이를 다시 시간 도메인으로 변환해주면 임의의 위상 오차를 포함하는 영상을 도출할 수 있다. 본 논문에서는 azimuth 방향에 따라 오차를 추가하고자 그 방향에 맞춰 푸리에 변환을 적용하였다. 또한 위상은 각도에 대한 값이기 때문에 각도의 크기에 따라 오차의 크기 역시 달라지게 된다. Degree값을 기준으로 0도부터 600도까지 오차를 추가해가며 영상 및 탐지 성능의 열화를 분석하고자 하였다.
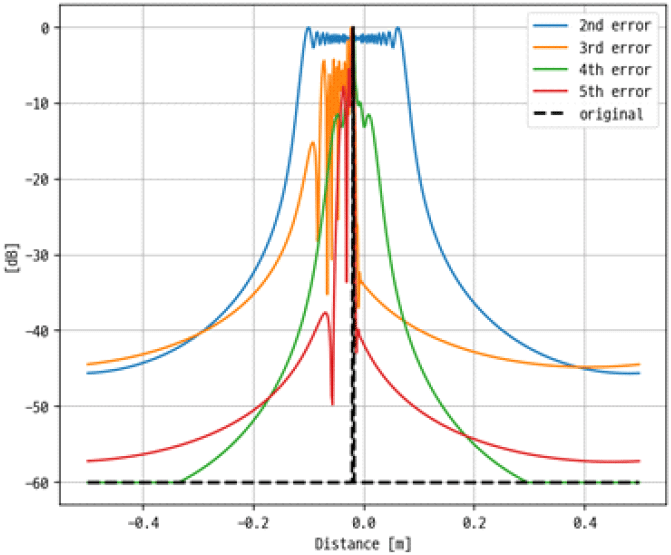
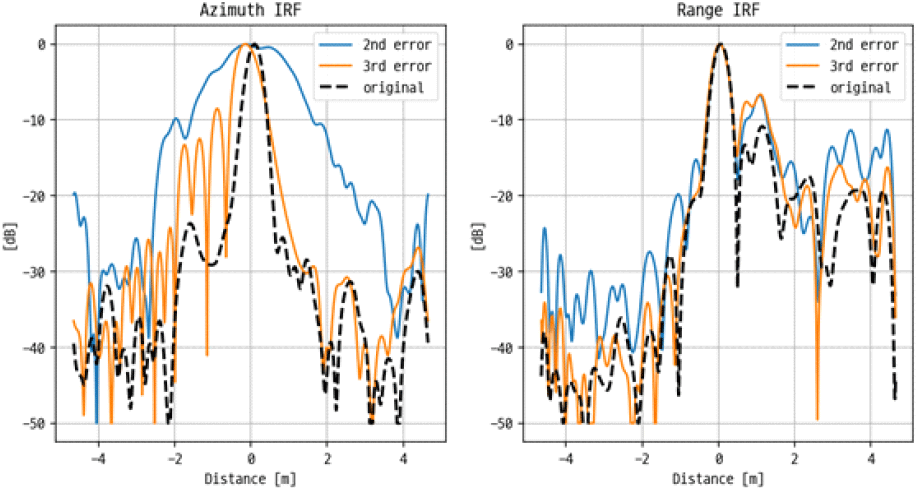
SAR 영상에 위상 오차가 추가될 경우 그 형태에 따라 영상이 열화되는 경향성이 다르게 나타난다. 대표적인 위상 오차로는 QPE(quadratic phase error)와 CPE(cubic phase error)가 있다. 이는 임의의 위상 오차를 정의할 때 기준 축에 대한 제곱수에 따라 구분할 수 있다. QPE의 경우 2차항, CPE의 경우 3차항의 위상 오차를 정의하기 때문에 각각 2차 위상 오차, 3차 위상 오차라 할 수 있다. 실제 영상에서는 다양한 오차들이 복합적으로 나타나지만 본 논문에서는 서로 다른 오차에 의한 영상 및 탐지 성능 열화를 개별적으로 확인해보고자 하였다. 그림 11은 이상적인 피크 신호를 기준으로 IRF(impulse response function) 변화 예시를 보여준다. 검정색 점선으로 표시된 원본 신호에 임의의 2차 위상 오차를 추가하면 파란색 실선처럼 피크 부분에 블러링이 발생하게 되고 3차 오차를 추가하면 주황색 실선처럼 sidelobe가 발생하며 신호가 한쪽으로 치우치게 된다. 실제 SAR 영상에 위상 오차를 추가해 본 결과는 그림 12를 통해 볼 수 있다. 그림 12의 윗줄은 샘플 영상에 300도 가량의 위상 오차를 추가한 결과이고 아랫줄은 해당 영상의 일부를 확대한 영상이다. 원본 영상과 비교했을 때 위상 오차가 추가되면서 영상 열화가 발생하는 것을 확인할 수 있다. 그림 13은 그림 12에서 점선의 원으로 표시된 점 표적에 2차 및 3차 위상 오차가 추가된 경우의 IRF 그래프이다. 실제 영상에서도 그림 11의 예시와 유사한 형태로 신호의 블러링 및 치우침이 발생하는 것을 확인하였다. 서로 다른 위상 오차를 추가했을 때의 azimuth resolution 및 PSLR(peak sidelobe ratio), ISLR(integrated sidelobe ratio)을 산출한 결과는 표 3과 같다. 위상 오차가 추가될 경우 영상의 성능 지표값이 저하됨을 정량적으로도 확인할 수 있다.

위와 같이 열화가 일어난 영상에 기구축되어있는 탐지 모델을 적용해 성능 변화를 확인해 보았다. 먼저 가장 기본적인 탐지기인 Faster RCNN을 기준으로 보았을 때의 결과는 그림 14 및 표 4와 같다. 오차의 정도가 커질수록 탐지 성능이 감소하고 성분 차수가 높아질수록 열화 정도는 감소하는 것으로 분석되었다.
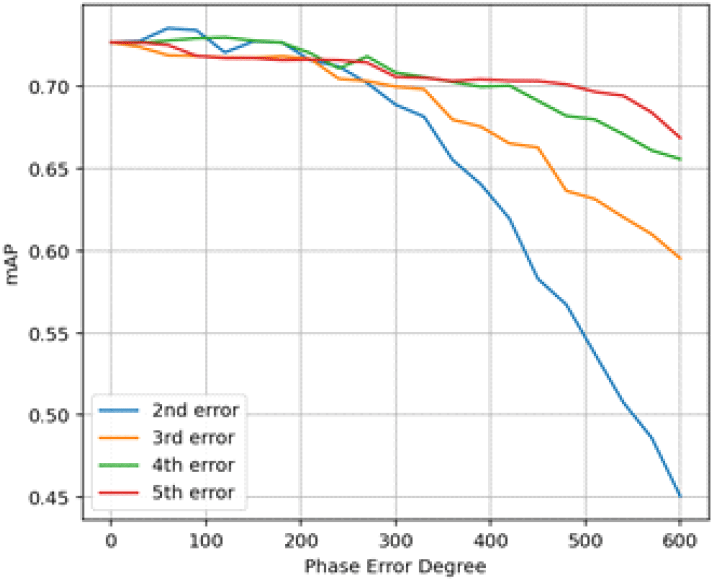
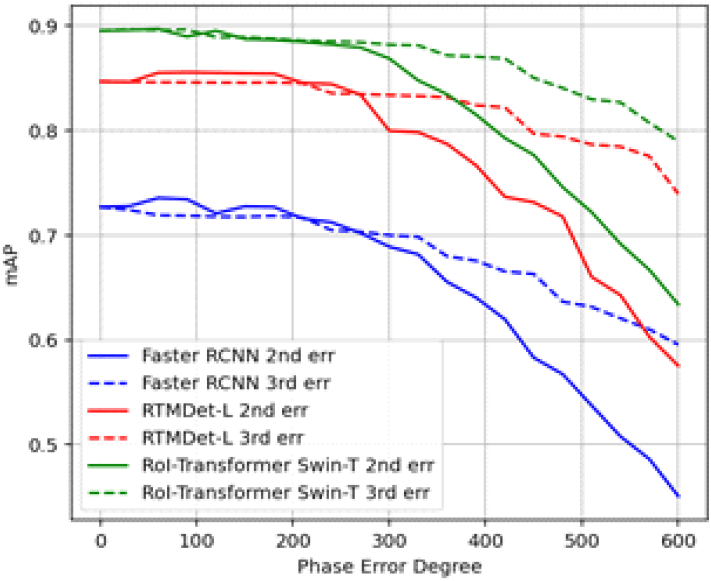
탐지 모델에 따른 차이 여부를 확인하기 위해 Faster RCNN 외에 기존 분석에서 좋은 성능을 보였던 RoI transformer와 RTMDet에 대해서도 동일한 분석을 수행하고자 탐지 성능에 가장 큰 영향을 주었던 2차 및 3차 오차를 적용해 mAP의 변화를 비교해 보았다. 그 결과는 그림 15 및 표 5와 같으며 세 모델 모두 유사한 경향성으로 성능 열화가 발생하는 것을 볼 수 있다. 또한 세 모델 모두 위상 오차 200도 정도까지는 베이스라인 대비 성능이 크게 하락하지 않는 것으로 확인하였다. 즉, 실제 SAR 영상에서 위상 오차를 발생시킬 수 있는 항공기 요동 및 시스템 내부 오차 등의 요소를 허용 범위 이내로 제어한다면 기구축된 모델을 활용해 SAR 영상에서의 지상 표적을 탐지하는 것이 가능하고 판단할 수 있다. 그 이상의 오차가 발생할 경우에는 탐지식별 네트워크의 성능을 보장하기 위해 열화가 발생한 영상을 기준으로 데이터셋을 추가 구축하여 모델 학습에 추가해 주어야 할 것이다.
Ⅴ. 결 론
본 연구에서는 SAR 영상에서의 지상 군사 표적 탐지식별에 대한 딥러닝 연구를 수행하기 위해 MSTAR 데이터셋을 활용한 탐지 데이터셋을 구축하였다. 다양한 탐지 모델에 대한 벤치마크를 통해 데이터셋을 검증하고 SAR 지상 표적 탐지 네트워크에 대한 성능을 분석하였다.
구축한 데이터셋으로 학습된 모델을 실제 항공 SAR 영상 등에 적용하기 위해서는 항공기 요동 및 시스템 내부 오차 등에 따른 위상 오차에 대한 고려가 필요하다. SAR 영상에 위상 오차가 추가될 경우 오차에 따른 영상 및 탐지 성능의 열화를 분석하였다. 결과적으로 위상 오차 200도까지는 탐지 성능 하락이 크지 않아 기구축 모델을 활용하는 것이 가능할 것이라고 판단하였다. 추후 실제 영상과 유사하게 다양한 오차들이 복합적으로 적용되는 경우에 대해서도 연구를 수행한다면 더 정확한 분석이 가능할 것이다.
이를 바탕으로 다양한 영상 오차를 고려하여 실제 영상에 활용 가능한 데이터셋을 추가 구축한다면 더욱 강건한 모델을 학습할 수 있을 것이다. 또한 탐지된 객체에 대한 식별 연구까지 반영하여 영상 오차에 대한 분석을 수행할 수 있다. 최종적으로 실제 SAR 영상에서 충분한 성능을 보장하는 지상 군사 표적 탐지식별을 위한 end-to-end 네트워크를 구축하고자 한다.


